
構造化データとは?SEOへの影響とBtoBサイトでの実装ポイント

構造化データとは、ページに書かれている情報を検索エンジンが理解しやすい形式で補足するための記述です。SEOの文脈では、schema.orgの語彙を使い、JSON-LDなどの形式でページの種類、著者、会社情報、パンくず、FAQ、サービス情報などを伝える時に使われます。
最初に結論から言うと、構造化データは検索順位を直接上げるための魔法ではありません。 しかし、ページ内容をGoogleに誤解なく伝え、リッチリザルトの対象になり得る情報を整理し、Search Consoleで技術的な問題を確認しやすくするという意味では、技術SEOの中でも実務価値の高い施策です。
Google公式の構造化データの仕組みでは、構造化データはページの情報を提供し、コンテンツを分類するための標準化された形式として説明されています。また、Googleがサポートしている構造化データは検索ギャラリーで確認できます。
ただし、構造化データを入れれば必ずリッチリザルトが表示されるわけではありません。Googleの構造化データに関する一般的なガイドラインでも、正しくマークアップされていても検索結果での表示は保証されないと説明されています。
構造化データで大切なのは、順位や装飾を狙う前に、ページにある情報を正しく整理して伝えることです。ここを間違えると、実装は増えているのに検索結果の改善にも問い合わせ導線にもつながらない、という状態になりやすくなります。
BtoBサイトの場合、構造化データは特に「記事」「サービスページ」「会社情報」「パンくず」「FAQ」「事例ページ」の整理で役立ちます。たとえば、コラム記事であればArticle、ページ階層であればBreadcrumbList、会社情報であればOrganization、支援内容であればServiceのように、ページの役割に合うschemaを選びます。
一方で、BtoB企業がやりがちな失敗もあります。存在しないFAQを構造化データだけに入れる、実際にはレビューがないのに評価情報を入れる、リッチリザルトに出したいという理由だけでページ本文と違う情報をマークアップする、検証しないまま全ページへ一括反映する、といった運用です。
本文に存在しないFAQ、架空のレビュー、実態と違う会社情報を構造化データに入れるのは避けてください。構造化データは検索エンジンに見せる裏技ではなく、ページの見える情報を機械にも伝えるための補助です。
この記事では、構造化データの意味、SEOへの影響、BtoBサイトで使いやすい種類、JSON-LDでの実装、検証方法、よくあるミス、AI検索時代の考え方、自社で確認する範囲と外部に相談する範囲まで整理します。
補足ボックス|この記事でわかること
- 構造化データとは何か
- 構造化データがSEOにどう関係するか
- 構造化データでできることとできないこと
- BtoBサイトで使いやすいschemaの種類
- JSON-LDで実装する時の基本手順
- Article、Breadcrumb、Organization、FAQの使い分け
- 実装するページの優先順位
- リッチリザルトテストとSearch Consoleでの検証方法
- 構造化データでよくあるミス
- AI検索時代に構造化データをどう扱うか
- 自社で確認する範囲と外部に相談する範囲
補足ボックス終了
構造化データはページ情報を検索エンジンに伝える補助線
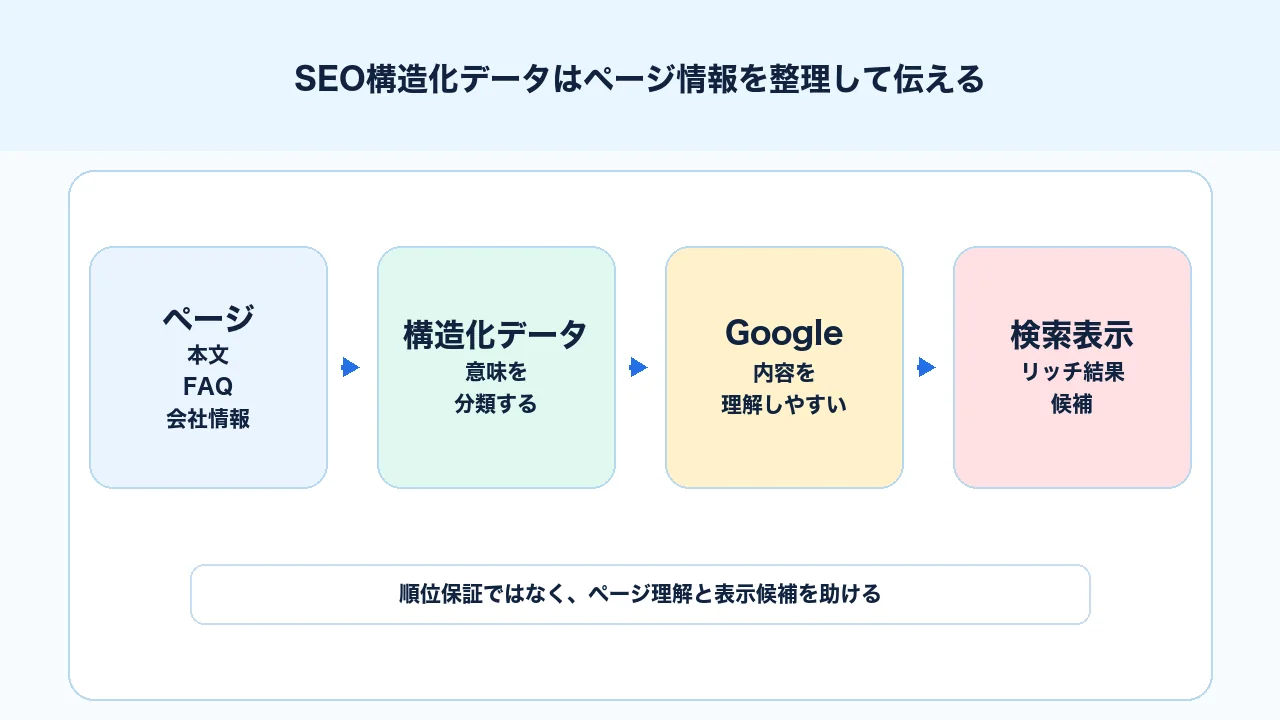
構造化データは、ページの内容を検索エンジンへ補足するための情報です。人間はページを読めば、この記事がコラムなのか、サービスページなのか、FAQなのか、会社情報なのかをある程度判断できます。しかし検索エンジンに対しては、本文、HTML構造、リンク、画像、メタ情報などから推測してもらうことになります。
そこで、schema.orgの語彙を使って「このページはArticleです」「この部分はパンくずです」「この組織名は会社名です」「この質問と回答はFAQです」と伝えるのが構造化データです。
構造化データは、検索エンジンに対してページ情報の意味を補足するものです。 HTMLだけでもページは読めますが、構造化データを使うことで、ページ種別や要素の関係をより明確に伝えやすくなります。
Googleは構造化データを理解すると、ページによってはリッチリザルトとして検索結果に特別な表示を出す場合があります。たとえば、パンくず、商品情報、レシピ、求人、イベント、動画、FAQなどです。ただし、どの種類が表示対象になるかはGoogleがサポートしている機能に限られます。
schema.org自体はGoogleだけのためのものではありません。schema.orgは、Web上の構造化データを表すための共通語彙です。Google、Bing、Yahoo、Yandexが関わってきた標準的な語彙で、Searchだけでなく、Web全体の情報整理に使われます。
実務で考えると、構造化データの役割は大きく3つあります。
| 役割 | 内容 | BtoBサイトでの例 |
|---|---|---|
| 情報理解の補助 | ページの種類や要素を伝える | Article、Organization、Breadcrumb |
| リッチリザルト候補 | Googleが対応する検索表示の対象にする | パンくず、動画、FAQなど |
| 運用確認 | Search Consoleやテストツールで問題を把握する | エラー、警告、無効項目の確認 |
ここで注意したいのは、構造化データは本文の代替ではないという点です。本文に書かれていない情報を構造化データだけに入れても、読者には伝わりません。Googleの一般ガイドラインでも、構造化データの内容はユーザーに見えるページ内容と一致している必要があるとされています。
構造化データは、見える本文を補強するために使うものです。読者に見えない情報を検索エンジンだけへ渡す発想ではなく、ページで説明している内容を、検索エンジンにも分かりやすい形式に変換する発想で使います。
BtoBサイトでいえば、サービスページに支援範囲、対象企業、導入までの流れが書かれているなら、ServiceやOrganizationの情報を検討できます。コラム記事に著者、更新日、見出し、FAQがあるなら、ArticleやFAQPageを検討できます。ページ階層が明確ならBreadcrumbListを検討できます。
綱脇耕輔の実務見解として、構造化データの相談を受ける時は、最初に「そのページは何を伝えるページか」を確認します。記事なのか、サービスなのか、事例なのか、資料ダウンロードなのか、会社情報なのか。この整理ができていない状態でschemaだけを選んでも、実装は増えるのに成果判断ができません。
構造化データは、ページ設計が整理されているほど効果的に使いやすくなります。 逆に、ページの目的、本文の内容、CTA、内部リンクが曖昧なまま構造化データを入れても、根本的な課題は残ります。
構造化データでできることとできないこと
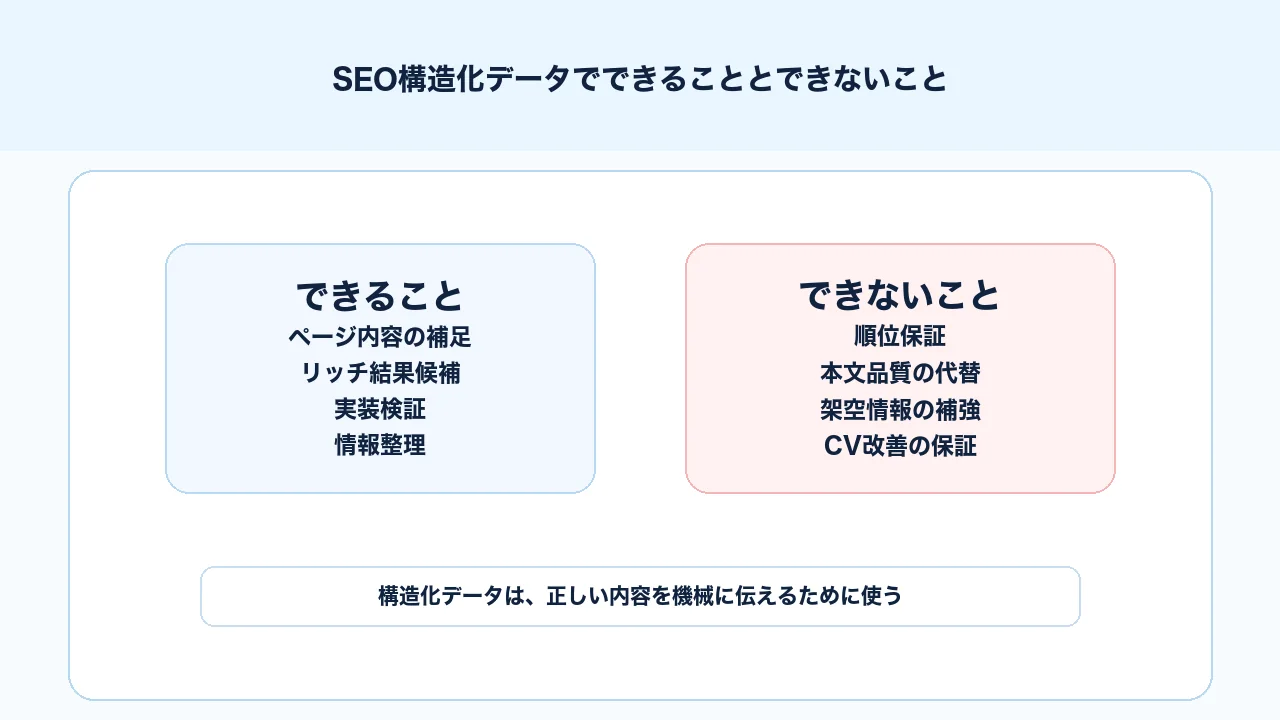
構造化データはSEOに関係しますが、できることとできないことを分けて理解する必要があります。特に「構造化データを入れれば順位が上がる」「schemaを増やせばAI検索に出やすくなる」といった短絡的な理解は避けたいところです。
構造化データでできることは、ページ情報を検索エンジンに伝えやすくすること、Googleがサポートするリッチリザルトの対象になり得ること、Search Consoleやリッチリザルトテストで技術的な問題を確認しやすくすることです。
一方で、構造化データでできないことは、低品質な本文を良質な本文に変えること、検索順位を保証すること、存在しない情報を正当化すること、問い合わせ導線の弱さを自動で解決することです。
| 項目 | できること | できないこと |
|---|---|---|
| 検索順位 | ページ理解の補助 | 順位上昇の保証 |
| 検索結果表示 | リッチリザルト候補 | 表示の保証 |
| 本文品質 | 情報の分類補助 | 低品質本文の改善 |
| FAQ | 可視FAQの補足 | 存在しないFAQの追加 |
| 会社情報 | 組織情報の整理 | 実態と違う情報の補強 |
| CV導線 | ページ役割の整理補助 | 問い合わせ増加の保証 |
Googleの一般ガイドラインでは、構造化データを正しく実装していても、検索結果で表示される保証はないと説明されています。これは非常に重要です。構造化データは、Googleに対して「このページにはこういう情報があります」と伝えるものですが、検索結果にどう表示するかはGoogle側の判断です。
構造化データは、順位やリッチリザルトを強制する命令ではありません。 実装後は、リッチリザルトテストで技術的に有効かを確認し、Search ConsoleでGoogleがどう認識しているかを確認します。
よくある誤解として、「構造化データはSEO効果があるのか」という問いがあります。この問いへの実務的な答えは、「直接的な順位保証としてではなく、検索結果での理解・表示候補・検証性を高める意味で価値がある」です。
たとえば、記事ページにArticle構造化データを入れても、本文が薄く、著者情報もなく、検索意図に答えていなければ、上位表示の根本改善にはなりません。逆に、本文品質、著者情報、更新日、内部リンク、サービス導線が整理された記事にArticleやBreadcrumbを入れると、ページ情報がより伝わりやすくなります。
構造化データは、良いページ設計を検索エンジンにも伝えやすくする補助線です。ページ設計が弱いままschemaだけを足すのではなく、本文、導線、計測、内部リンクとセットで見てください。
BtoBサイトでは、構造化データを「検索結果の装飾」だけで捉えると優先順位を間違えます。BtoBのリード獲得では、検索結果で見つけてもらう、記事で疑問を解消する、サービスページへ進む、相談する、という導線全体が重要です。構造化データは、この導線の中でページの意味を整理する技術施策の一つです。
試算例として、月間自然検索流入が2,000あるコラム群に対して、パンくず、Article、著者情報、内部リンク、CTAを整理したとします。この時、構造化データ単体の効果だけを切り出すのは難しいですが、Search Consoleで拡張機能のエラーが減り、ページ種別が整理され、GA4でサービスページ遷移が追いやすくなれば、改善判断の精度は上がります。これは実績値ではなく仮説モデルですが、構造化データを「順位施策」ではなく「情報と計測の整理」として見るための考え方です。
BtoBサイトで使いやすい構造化データの種類
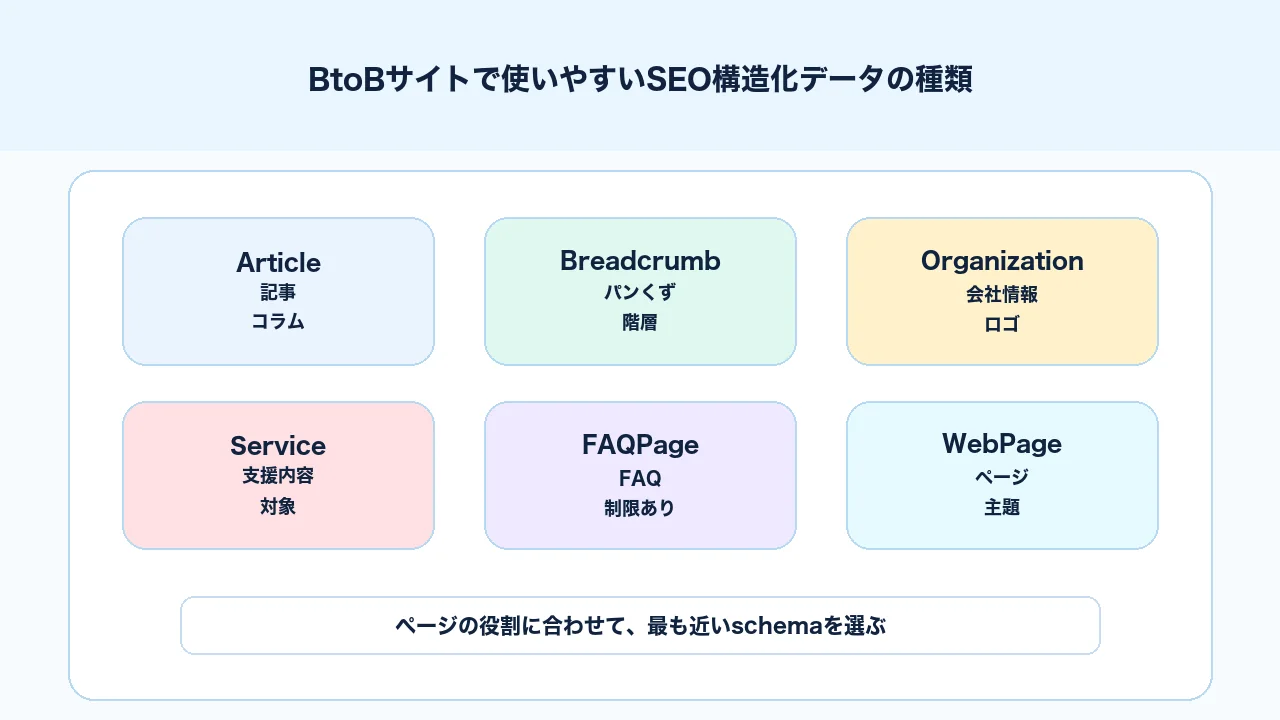
BtoBサイトで構造化データを考える時は、Googleがサポートしている種類をすべて入れようとする必要はありません。まずは、自社サイトのページ種別に合うものを選びます。
代表的に検討しやすいのは、Article、BreadcrumbList、Organization、WebPage、Service、FAQPageです。ECサイトであればProductやReviewも関係しますが、BtoBのコンサルティングや広告運用、SEO支援のようなサービスサイトでは、実態に合わないProductやReviewを無理に使うべきではありません。
| 構造化データ | 向いているページ | BtoBでの使い所 |
|---|---|---|
| Article | コラム、ニュース、解説記事 | 著者、更新日、記事内容の整理 |
| BreadcrumbList | ほぼ全ページ | サイト階層と導線の整理 |
| Organization | 会社情報、トップ、共通テンプレ | 会社名、ロゴ、URL、SNSなど |
| WebPage | 固定ページ全般 | ページ主題の補足 |
| Service | サービスページ | 提供サービス、対象領域の整理 |
| FAQPage | FAQがあるページ | 可視FAQの補足。ただし表示対象には制限あり |
| VideoObject | 動画掲載ページ | 動画コンテンツの補足 |
| Event | セミナー、ウェビナー | 開催日時、場所、参加方法の整理 |
BtoBサイトでは、Article、BreadcrumbList、Organizationから検討すると始めやすいです。 この3つは多くの企業サイトで使いやすく、記事、階層、会社情報という基本的な情報整理に関わります。
Serviceは、サービスページで検討できます。ただし、schema.orgのServiceを使う時は、ページ本文に実際の支援内容、対象領域、提供会社、問い合わせ導線が書かれていることが前提です。構造化データだけに詳細を入れるのではなく、本文でも説明しておく必要があります。
FAQPageは注意が必要です。2026年時点のGoogle公式ドキュメントでは、FAQリッチリザルトは政府機関または保健衛生関連の有名で権威あるサイト向けに限定されています。つまり、一般的なBtoB企業がFAQPageを入れても、従来のようなFAQリッチリザルト表示を期待するのは現実的ではありません。
FAQPageは「入れれば検索結果で目立つ」と考えるのではなく、可視FAQを整理する補助として慎重に扱うべきです。FAQ自体は読者の疑問を回収する意味で有効ですが、構造化データの表示効果だけを目的にしない方がよいです。
また、レビューや評価の構造化データも注意してください。実際に第三者レビューや評価が存在しないのに、星評価を出したいという理由でReviewやAggregateRatingを入れるのは危険です。Googleのガイドラインでは、誤解を招く内容やページにない情報を構造化データに入れることは避けるべきとされています。
実態のないレビューや評価を入れると、構造化データの手動対策やリッチリザルト対象外につながる可能性があります。見た目を良くするためにschemaを選ぶのではなく、ページに存在する情報に合うschemaを選んでください。
綱脇耕輔の実務見解として、BtoBサイトでは「どのschemaを入れるか」よりも「どのページ群に共通ルールで入れるか」が重要です。コラムテンプレート、サービスページテンプレート、事例テンプレート、カテゴリページテンプレートごとにルールを決めると、運用が安定します。
構造化データの基本実装はJSON-LDで考える
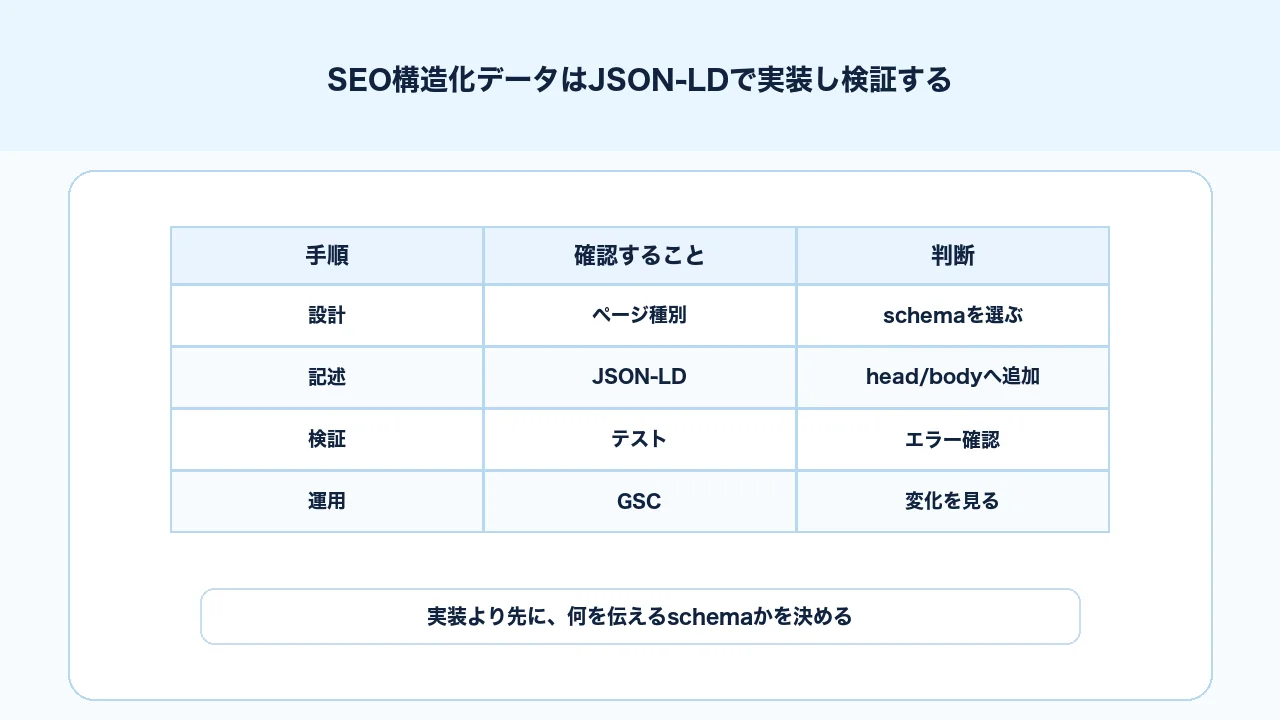
構造化データの実装形式には、JSON-LD、Microdata、RDFaがあります。Googleの一般的な構造化データガイドラインでは、JSON-LDが推奨形式として扱われています。実務上も、HTML本文と分離して管理しやすく、テンプレートやCMSで扱いやすいため、まずJSON-LDで考えるのが現実的です。
JSON-LDは、JavaScriptのオブジェクトに近い形式で、ページのheadまたはbodyに記述できます。たとえばArticleであれば、記事タイトル、著者、公開日、更新日、画像、URLなどをまとめて記述します。
ただし、この記事ではコードの丸暗記よりも、実装前に決めるべき設計を重視します。構造化データの実装は、次の順番で進めます。
1. 対象ページの種類を決める 2. ページ本文に表示されている情報を確認する 3. Googleがサポートする構造化データの種類を確認する 4. schema.orgで必要なプロパティを確認する 5. JSON-LDでテンプレート化する 6. リッチリザルトテストで検証する 7. Search Consoleで公開後の状態を見る 8. エラーや警告があればテンプレート単位で修正する
JSON-LD実装で重要なのは、コードを書く前にページ種別と情報項目を決めることです。 schemaを選ぶ前に、対象ページが記事なのか、サービスなのか、会社情報なのか、FAQなのかを整理してください。
実装時に確認したい項目は次の通りです。
| 確認項目 | 見ること | 理由 |
|---|---|---|
| ページ種別 | Article、Service、Organizationなど | schema選定の土台になる |
| 可視内容 | 本文に表示されているか | ガイドライン違反を避ける |
| 必須プロパティ | Googleの要件を満たすか | リッチリザルト対象の前提 |
| 推奨プロパティ | 追加情報があるか | 情報の補足に役立つ |
| 画像URL | クロール可能か | 検索結果表示に関わる |
| 日付 | 公開日・更新日が正しいか | 記事情報の信頼性に関わる |
| 著者 | 実在する著者か | E-E-A-Tの判断材料になる |
| 検証 | リッチリザルトテストで確認したか | エラーを早期に見つける |
BtoBサイトでは、CMSのテーマやプラグインが自動で構造化データを出していることがあります。WordPress、Ghost、microCMS、Next.js、Astroなど、環境によって出力方法は異なります。まずは現在のページにどの構造化データが出ているかを確認し、重複や矛盾がないかを見ます。
既存CMSがすでに出しているschemaを確認せずに追加実装すると、重複や不整合が起きやすくなります。たとえば、テーマ側でArticleを出し、プラグイン側でもArticleを出し、さらにカスタムコードでもArticleを出してしまうと、管理が複雑になります。
実務では、対象ページを数ページ選び、リッチリザルトテストで現在の状態を確認してから、テンプレート単位で改善します。いきなり全ページに一括反映すると、全ページに同じエラーが広がることがあります。
Article・Breadcrumb・Organization・FAQの使い分け
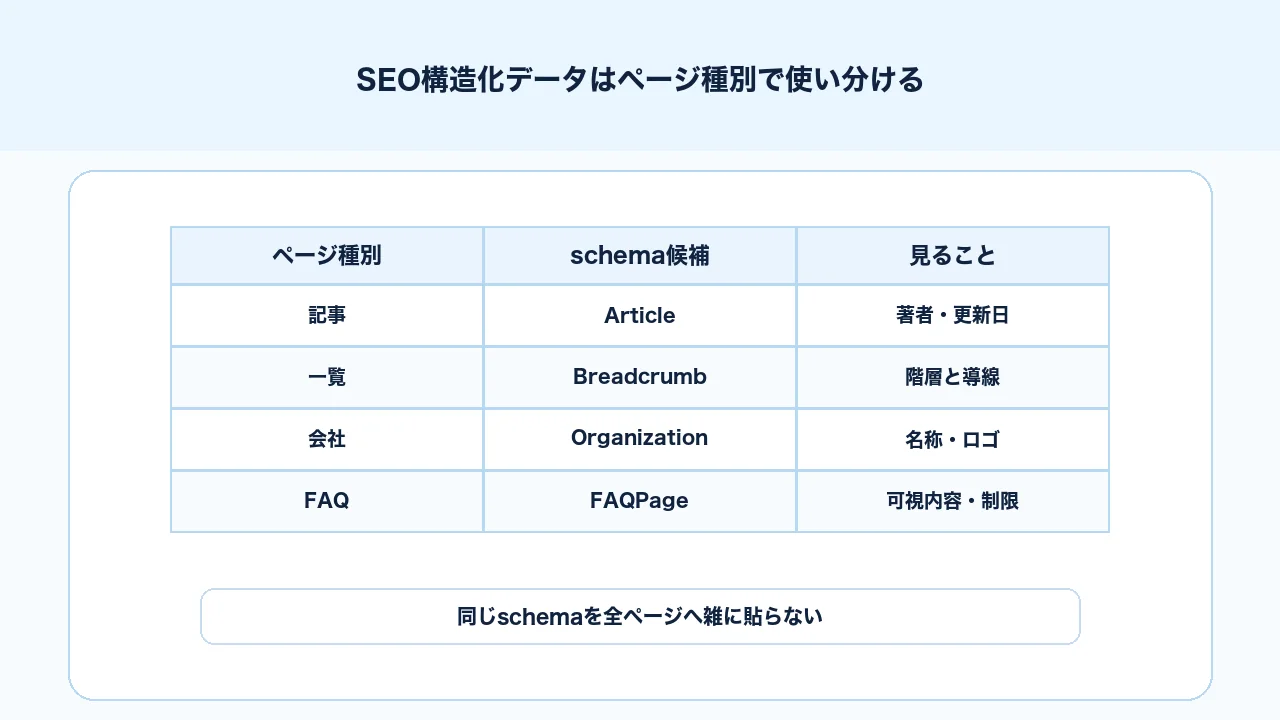
構造化データの実装では、同じschemaを全ページに入れるのではなく、ページ種別に合わせて使い分けます。BtoBサイトで特に扱いやすいのは、Article、BreadcrumbList、Organization、FAQPageです。
Articleは、コラム記事やニュース記事に使います。記事タイトル、著者、公開日、更新日、画像、本文の主題などを整理できます。SEOメディアの記事では、Articleを使うことで「この記事は誰が、いつ公開し、どのような内容を扱っているのか」を伝えやすくなります。
BreadcrumbListは、パンくずリストを伝える構造化データです。ページがサイト内でどの階層にあるかを示すため、サービス、コラム、カテゴリ、タグ、事例など、ほぼ全ページで検討できます。
Organizationは、会社情報を伝える構造化データです。会社名、URL、ロゴ、SNS、連絡先などを整理できます。BtoBサイトでは、トップページや会社情報ページ、共通ヘッダーでの出力を検討します。
FAQPageは、ページ内にFAQがあり、質問と回答がユーザーに見える場合に検討します。ただし、前述の通り、GoogleのFAQリッチリザルトは政府機関または保健衛生関連サイト中心に制限されているため、一般的なBtoBサイトでは「表示されるから入れる」ではなく、「FAQをページ内で整理する補助」として扱います。
| ページ種別 | 優先schema | 注意点 |
|---|---|---|
| コラム記事 | Article、BreadcrumbList | 著者・更新日・画像を整える |
| サービスページ | Service、BreadcrumbList、Organization | 本文に支援内容を明記する |
| 会社情報 | Organization、WebPage | 実態と一致させる |
| FAQページ | FAQPage | 可視FAQのみ。表示対象の制限を理解する |
| 事例ページ | ArticleまたはWebPage、BreadcrumbList | 顧客名や成果の公開可否を確認する |
| セミナー | Event、BreadcrumbList | 日時、場所、申込導線を正確に扱う |
schemaは、ページの目的と本文内容に合わせて選びます。 全ページに同じJSON-LDを貼るのではなく、テンプレートごとに必要な情報を整理してください。
記事ページではArticleとBreadcrumbListが基本です。著者情報や更新日を本文やテーマ側で出している場合は、構造化データでも整合させます。著者名がページに表示されていないのに、構造化データだけに著者を入れると、読者にとっては確認できない情報になります。
サービスページでは、ServiceやOrganizationを検討します。ただし、ServiceはGoogleのリッチリザルトとして大きく表示されることを期待するものではなく、サービス情報の意味を整理する目的で使います。支援範囲、対象企業、提供会社、相談導線が本文にあるかを確認します。
構造化データは、ページ本文・テーマ表示・会社情報・著者情報とセットで整合させる必要があります。CMSの設定だけを見ていても、本文に表示されていない情報や古い会社情報が残っていることがあります。
No21のE-E-A-T記事で扱うような著者情報や信頼性の出し方は、構造化データだけで完結しません。構造化データは、著者情報や会社情報を検索エンジンに伝えやすくする補助ですが、読者に見えるプロフィール、実務経験、引用元、更新履歴が整っていることが前提です。
構造化データを実装するページの優先順位

構造化データは、全ページに一気に入れようとすると運用負荷が高くなります。特にBtoBサイトでは、問い合わせに近いページ、テンプレート化しやすいページ、エラー検証しやすいページから優先すると進めやすくなります。
まず確認したいのは、現在のサイトにどのページ群があるかです。サービスページ、コラム記事、事例ページ、会社情報、セミナー、ホワイトペーパー、タグ一覧、カテゴリ一覧、資料LPなどに分けます。そのうえで、検索流入があるか、問い合わせに近いか、テンプレートが共通かを見ます。
| 優先度 | ページ群 | 理由 |
|---|---|---|
| 高 | サービスページ | 問い合わせ導線に近い |
| 高 | コラム記事 | ArticleとBreadcrumbをテンプレート化しやすい |
| 高 | 会社情報・トップ | Organizationを整えやすい |
| 中 | 事例ページ | 業種や課題別の導線に関係する |
| 中 | セミナー・イベント | Eventを使える場合がある |
| 中 | FAQページ | 可視FAQがある場合のみ検討 |
| 低 | タグ一覧・薄い一覧 | 独自価値がなければ先に内容設計を見直す |
最初に見るべきなのは、問い合わせに近く、テンプレートで安定して反映できるページです。 技術SEOでは、実装できる場所から手をつけるより、事業上の影響が大きく、検証しやすい場所から始める方が成果判断しやすくなります。
たとえば、SEO支援サービスページ、広告運用サービスページ、GA4設定支援ページなどがある場合、ServiceやOrganization、BreadcrumbListの整合性を確認します。コラム記事が多数ある場合は、Article、著者、更新日、画像、パンくず、FAQの出力をテンプレート単位で確認します。
Search Consoleで構造化データのエラーが出ている場合は、個別URLではなくテンプレート単位で見ることが重要です。1記事だけのエラーなのか、記事テンプレート全体のエラーなのかで対応が変わります。
構造化データの優先順位は、検索流入、問い合わせ導線、テンプレート影響、検証しやすさで決めます。なんとなく全ページに入れるのではなく、どのページ群から改善するかを決めて進めます。
綱脇耕輔の実務見解として、BtoBサイトでは「サービスページとコラム記事の接続」が重要です。コラム記事にArticleやBreadcrumbが整っていても、サービスページへ自然に進めないなら問い合わせにはつながりません。構造化データは情報整理の一部として扱い、内部リンクやCTAも同時に確認します。
リッチリザルトテストとSearch Consoleで検証する
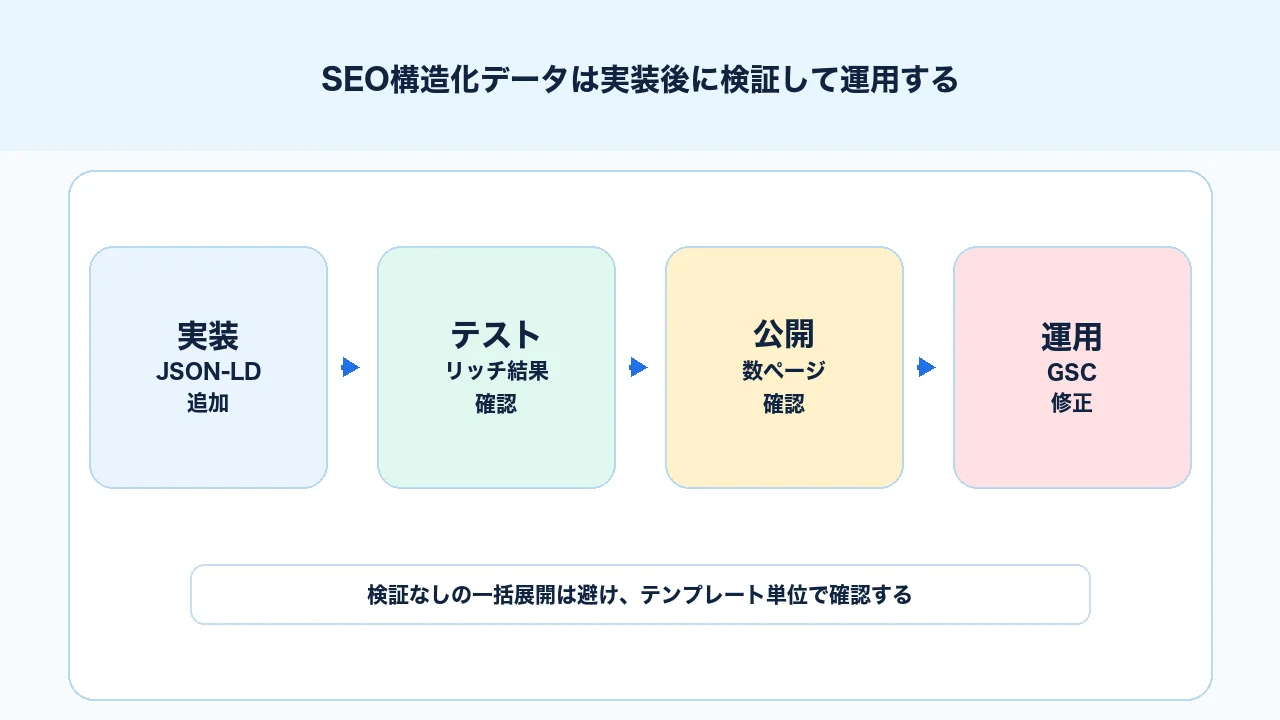
構造化データは、実装して終わりではありません。実装後は、Googleのリッチリザルトテストで技術的に確認し、公開後はSearch Consoleで問題が出ていないかを確認します。
リッチリザルトテストでは、URLまたはコードを入力して、Googleが検出できる構造化データや、リッチリザルト対象のエラーを確認できます。公開前にコードを確認する場合はコード入力、公開済みページを確認する場合はURL入力を使います。
検証の基本手順は次の通りです。
1. 対象ページのURLをリッチリザルトテストに入力する 2. 検出された構造化データの種類を確認する 3. エラーと警告を確認する 4. 必須プロパティの不足を修正する 5. 可視本文と構造化データの内容が一致しているか確認する 6. 数ページで問題がなければテンプレート単位で反映する 7. Search Consoleで公開後のエラーや有効項目を確認する
リッチリザルトテストは、表示保証ツールではなく、構造化データの検証ツールです。 テストで有効と出ても、検索結果で必ずリッチリザルトが出るわけではありません。
Search Consoleでは、構造化データに関連する拡張機能レポートや、検出された問題、URL検査を確認します。新しいテンプレートを公開した後、エラーが増えていないか、特定のページ群だけ問題が出ていないかを見ることが重要です。
Google公式のFAQPageドキュメントでも、構造化データを公開した後は、Search ConsoleでリッチリザルトステータスレポートやURL検査を使って確認する流れが説明されています。これはFAQに限らず、構造化データ全般の運用にも通じる考え方です。
| 検証箇所 | 使うツール | 確認内容 |
|---|---|---|
| 実装直後 | リッチリザルトテスト | 検出、エラー、警告 |
| 公開後 | Search Console | 有効項目、無効項目、対象URL |
| 個別URL | URL検査 | Googleが取得できるか |
| テンプレート変更後 | Search Console | エラーの増減 |
| 定期確認 | Search Console・GA4 | 表示、クリック、回遊、CV |
構造化データは、実装・検証・公開後監視までをセットで運用します。実装者がコードを入れただけで終わると、エラーが出ても誰も気づかない状態になります。
特にCMSやテーマを更新した時、プラグインを変えた時、著者プロフィールを変更した時、会社名やロゴを変えた時、FAQブロックを追加した時は、構造化データも変わる可能性があります。変更のたびに全ページを確認する必要はありませんが、代表ページで検証するルールは作っておきたいところです。
構造化データでよくあるミス
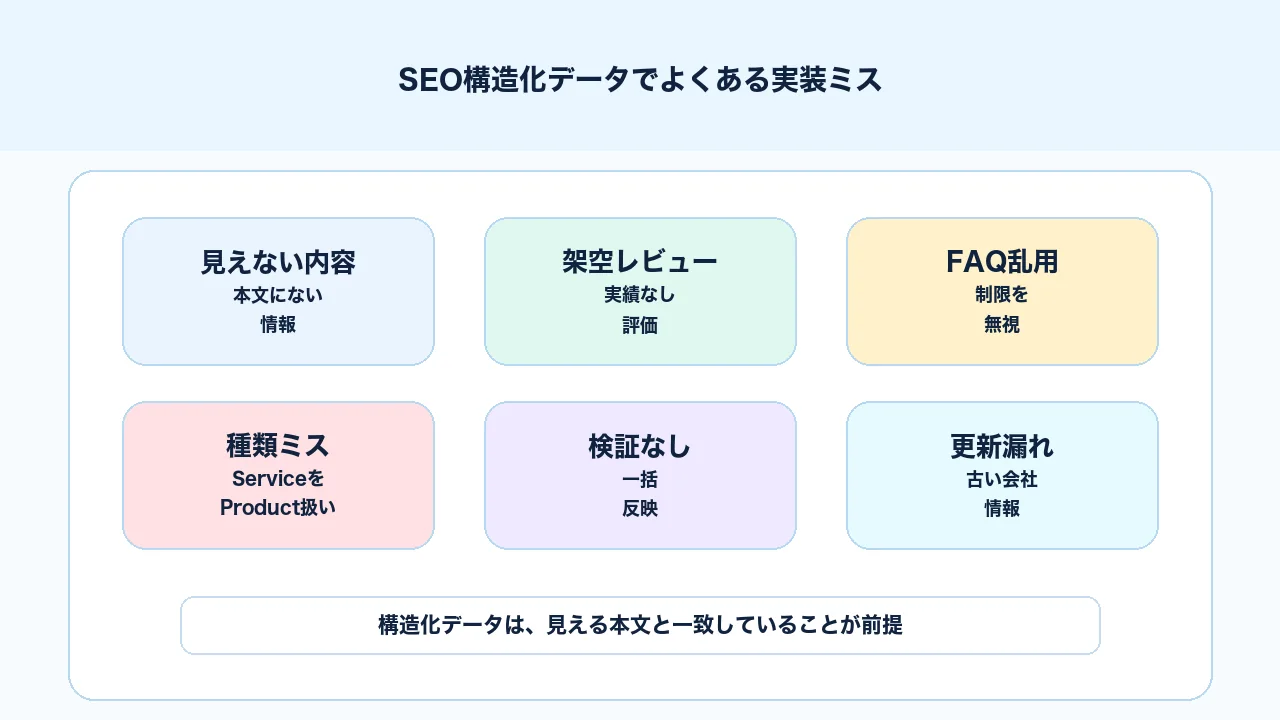
構造化データでよくあるミスは、コードの文法ミスだけではありません。むしろ実務では、ページの実態と構造化データの内容がずれている、テンプレートが重複している、FAQやレビューを過剰に入れている、検証しないまま公開している、といった運用ミスが多くなります。
代表的なミスを整理します。
| ミス | 起きる問題 | 対応 |
|---|---|---|
| 本文にない情報を入れる | ガイドライン違反の可能性 | 可視本文と一致させる |
| 架空レビューを入れる | 誤解を招く情報になる | 実在レビューのみ扱う |
| FAQPageを乱用する | 表示期待と実態がずれる | 制限を理解して使う |
| schema種類を間違える | ページ情報が伝わりにくい | ページ種別から選ぶ |
| 複数出力される | 管理が複雑になる | テーマ・プラグインを確認 |
| 画像URLがクロール不可 | 画像情報が使われない | URL検査で確認する |
| 古い会社情報が残る | 信頼性が下がる | Organizationを更新する |
| 検証なしで一括公開 | 全ページにエラーが出る | 代表URLで確認する |
構造化データのミスは、検索エンジンだけでなく読者の信頼にも関わります。 会社情報、著者情報、FAQ、レビュー、商品情報のような要素は、実態と一致していることが前提です。
特に注意したいのはFAQです。FAQは読者の疑問を回収するためには有効ですが、検索結果で目立たせるためだけに同じ質問を全ページへ入れたり、本文にない回答を構造化データだけへ入れたりするのは避けるべきです。
FAQを入れる場合は、ページ本文に質問と回答が見える形で掲載し、そのページの内容に関係するものに絞ります。重複するFAQを大量に使い回すより、ページごとの読者の疑問に合わせて作る方が自然です。
構造化データは、検索結果を操作するためではなく、ページの情報を正しく伝えるために使います。この前提があると、過剰なFAQ、架空のレビュー、関係のないschema追加を避けやすくなります。
もう一つのミスは、構造化データの実装担当とSEO担当、コンテンツ担当、サイト運用担当が分かれていることです。たとえば、記事担当が著者情報を変更したのに、テーマ側のArticle構造化データが古い著者を出し続けることがあります。サービス名が変わったのにOrganizationやServiceが旧名称のまま、ということも起きます。
そのため、構造化データは一度入れたら終わりではなく、サイト更新ルールに含める必要があります。会社名、ロゴ、著者、サービス名、URL、パンくず、FAQ、記事更新日が変わった時に、構造化データも確認する運用を作ってください。
AI検索時代でも構造化データは情報整理に役立つ
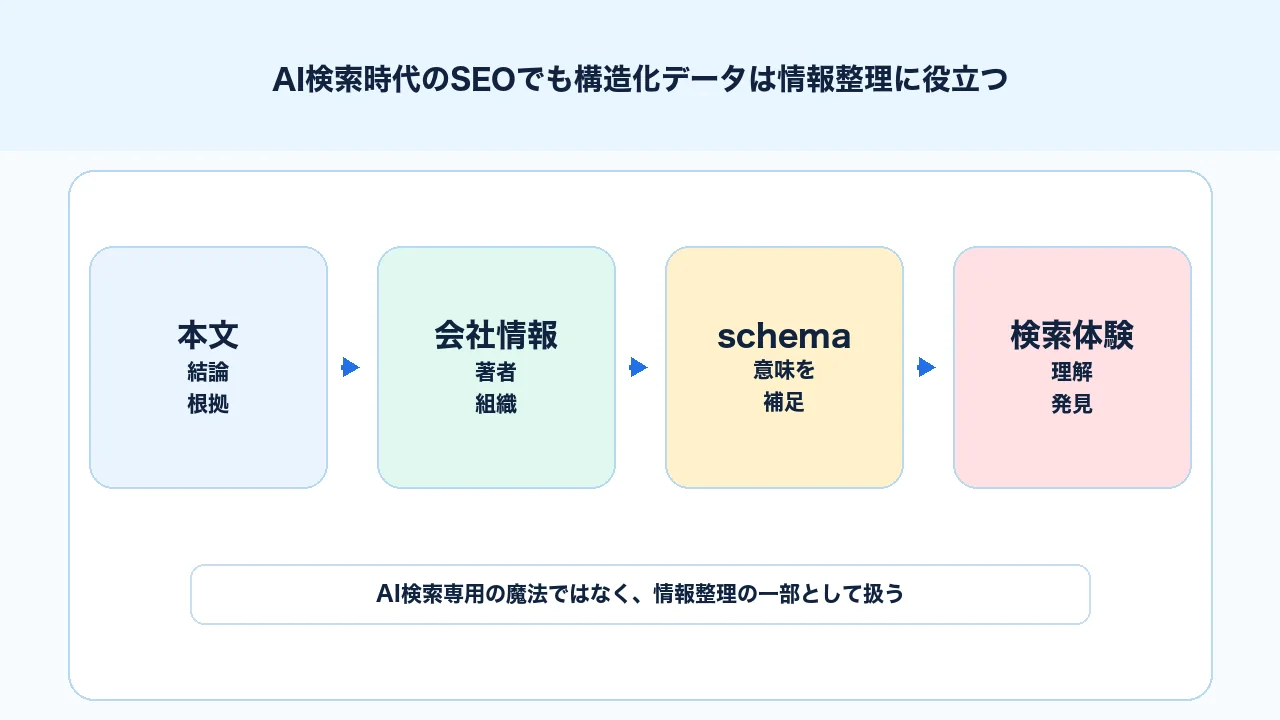
AI検索やAI Overviews、AI Modeの話題が増えると、「AI検索に出るために専用の構造化データが必要なのか」という質問が出てきます。結論として、構造化データはAI検索専用の魔法ではありません。
Google公式のAI機能とウェブサイトでは、AI機能に対しても従来のSEOのベストプラクティスが有効であること、構造化データはページ上の見えるテキストと一致している必要があることが説明されています。
つまり、AI検索時代でもやるべきことは、専用の裏技を探すことではありません。読者にとって分かりやすい本文、正確な会社情報、信頼できる引用、明確な著者情報、ページの役割に合った構造化データを整えることです。
AI検索時代の構造化データは、AIに特別対応するためではなく、ページ情報を整理する一部として扱います。 「AIに読ませるため」ではなく、「人間にも機械にも誤解されにくい情報設計にするため」と考える方が実務的です。
BtoBサイトでは、AI検索に直接出るかどうかだけでなく、会社名、サービス名、支援領域、著者、実績、記事の主題がサイト内で一貫しているかが重要です。Organization、Article、Breadcrumb、Serviceなどは、その一貫性を補助する情報として使えます。
No55のLLMO記事で扱うような用語整理やAI検索全体の考え方は、構造化データとは別に深掘りした方がよいテーマです。本記事では、AI検索対策全体ではなく、構造化データを情報整理の技術施策として扱います。
AI検索時代でも、構造化データだけで露出を保証することはできません。ただし、ページの主題、会社情報、著者、階層、FAQを整理しておくことは、検索体験が変わっても無駄になりにくい基礎整備です。
綱脇耕輔の実務見解として、AI検索時代のSEOでは「情報がどこにあり、誰が書き、どの会社が提供し、どのサービスに関係するか」を明確にすることが重要です。構造化データは、その情報整理をコード側でも支える要素です。
ただし、AI検索を理由にschemaを過剰実装する必要はありません。まずは通常の検索、記事品質、会社情報、サービスページ、FAQ、内部リンク、計測を整え、そのうえで構造化データを正しく実装します。
自社で確認する範囲と外部に相談する範囲

構造化データは、基本的な確認であれば自社でも進められます。一方で、テンプレート設計、大量ページへの反映、Search Consoleのエラー原因特定、CMSやフロントエンドの実装、問い合わせ導線まで含めた改善は、外部に相談した方が早い場合があります。
まず自社で確認できる範囲は次の通りです。
- リッチリザルトテストで主要ページを確認する
- Search Consoleで構造化データ関連のエラーを見る
- 記事ページに著者、公開日、更新日が表示されているか確認する
- パンくずがサイト上で正しく表示されているか確認する
- 会社名、ロゴ、SNS、問い合わせ先が古くないか確認する
- FAQが本文に表示されているか確認する
- サービスページに支援内容と問い合わせ導線があるか確認する
自社で最初に見るべきなのは、実装コードよりもページに表示されている情報です。 ページ上に必要な情報がなければ、構造化データを入れても不自然になります。
外部に相談した方がよいケースは次の通りです。
- Search Consoleで構造化データエラーが大量に出ている
- CMSやテーマが複数のschemaを出している
- サービスページ、記事、事例、FAQのテンプレートを整理したい
- AI検索やリッチリザルトを踏まえて情報設計を見直したい
- 著者情報、会社情報、記事品質、構造化データをまとめて改善したい
- 実装後のCV導線やGA4計測まで確認したい
外部に相談する時は、構造化データの実装だけでなく、ページ設計・計測・問い合わせ導線まで見てくれるかを確認してください。schemaだけ入れても、読者がサービスページへ進めない、フォームに到達できない、GA4で行動を見られない状態では、事業成果にはつながりにくいです。
構造化データ相談で事前に整理しておくとよい情報は、主要URL、CMSや開発環境、Search Consoleのエラー画面、対象ページの種類、会社情報の正確な表記、著者プロフィール、サービスページのURL、問い合わせ導線です。
| 相談前に整理する情報 | 理由 |
|---|---|
| 主要URL一覧 | 対象ページを把握するため |
| ページ種別 | schemaを選ぶため |
| Search Consoleのエラー | 優先度を判断するため |
| CMS・テーマ・プラグイン | 実装方法を決めるため |
| 会社情報・ロゴ | Organizationを整えるため |
| 著者情報 | ArticleとE-E-A-Tを整えるため |
| サービスページURL | CTAとServiceを接続するため |
| GA4・CV計測 | 実装後の成果を見るため |
綱脇耕輔の実務見解として、構造化データは単発の技術実装として切り出すより、技術SEO診断の一部として見る方が判断しやすいです。URL設計、パンくず、canonical、noindex、XMLサイトマップ、著者情報、内部リンク、CTA、Search Consoleの拡張機能をまとめて確認すると、優先順位が見えます。
構造化データの実装前チェックリスト
構造化データを入れる前に、次のチェックリストで確認しておくと、無駄な実装やガイドライン違反を避けやすくなります。
| チェック項目 | 確認内容 | OKの状態 |
|---|---|---|
| ページ目的 | 記事、サービス、会社情報など | ページ種別が明確 |
| 可視本文 | schemaに入れる情報が本文にあるか | 読者にも見える |
| 著者情報 | 記事著者が表示されているか | 実在プロフィールがある |
| 更新日 | 記事の更新日が正しいか | テーマ表示と一致 |
| パンくず | サイト階層が正しいか | Breadcrumbと一致 |
| 会社情報 | 名称、URL、ロゴが正しいか | Organizationと一致 |
| FAQ | 質問と回答が本文にあるか | そのページ固有のFAQ |
| 画像 | 画像URLがクロール可能か | URL検査で問題なし |
| 検証 | テストツールで確認したか | エラーなしまたは修正方針あり |
| 運用 | 誰が更新するか決まっているか | 変更時の確認者がいる |
構造化データの品質は、実装前の情報整理でほぼ決まります。 コードを書いてから考えるのではなく、ページ目的、可視情報、schema種類、検証方法、運用者を先に決めます。
このチェックリストは、外部に相談する時の整理にも使えます。もし半分以上が未整理であれば、構造化データの実装より先に、記事テンプレート、サービスページ、会社情報、FAQ、著者表示を整えた方がよい可能性があります。
特にBtoBサイトでは、記事だけでなくサービスページへの導線が重要です。構造化データを整えても、記事からサービスページに進めない、サービスページの情報が薄い、フォームが遠い、計測できていない状態では、問い合わせにはつながりにくくなります。
構造化データの実装判断は、SEO表示だけでなく、読者が問い合わせに進む導線まで含めて考えます。これは技術SEOを事業成果に接続するうえで重要な視点です。
まとめ
構造化データとは、ページにある情報を検索エンジンへ分かりやすく伝えるための補助情報です。SEOでは、schema.orgの語彙とJSON-LDなどの形式を使って、記事、パンくず、会社情報、FAQ、サービス情報などを整理します。
この記事で押さえたい結論は、構造化データは順位保証のためではなく、ページ情報を正しく整理して伝えるために使う ということです。リッチリザルトの対象になる可能性はありますが、表示は保証されません。本文の品質、著者情報、会社情報、内部リンク、CTA、Search Consoleでの検証とセットで考える必要があります。
BtoBサイトでは、Article、BreadcrumbList、Organization、Service、FAQPageなどをページ種別に合わせて検討します。特に、コラム記事、サービスページ、会社情報、パンくずは優先的に確認しやすい領域です。
一方で、FAQPageやReviewを過剰に使う、本文にない情報を入れる、検証せず全ページへ一括反映する、CMSの出力を確認せず重複させる、といった運用は避けるべきです。
自社で確認する場合は、まずリッチリザルトテスト、Search Console、主要ページの可視情報、著者情報、パンくず、会社情報を確認してください。判断に迷う場合は、構造化データ単体ではなく、技術SEO診断としてURL設計、記事テンプレート、会社情報、内部リンク、CTA、GA4計測までまとめて確認する方が実務的です。
よくある質問
構造化データはSEOに効果がありますか?
構造化データは検索順位を直接保証するものではありません。ただし、ページ内容を検索エンジンに伝えやすくし、Googleがサポートするリッチリザルトの対象になり得るため、技術SEOの基礎整備として価値があります。
構造化データを入れるとリッチリザルトは必ず表示されますか?
必ず表示されるわけではありません。Google公式ガイドラインでも、正しくマークアップされていても検索結果での表示は保証されないと説明されています。テストで有効でも、最終的な表示はGoogle側の判断です。
BtoBサイトではどの構造化データから入れるべきですか?
まずはArticle、BreadcrumbList、Organizationを確認しやすいです。サービスページではServiceも検討できます。FAQPageはページ内に可視FAQがある場合に検討しますが、GoogleのFAQリッチリザルトは政府機関や保健衛生関連サイト中心に制限されているため、過度に期待しない方がよいです。
JSON-LD、Microdata、RDFaのどれを使うべきですか?
GoogleはJSON-LDを推奨形式として扱っています。実務でも、HTML本文と分けて管理しやすく、CMSやテンプレートで扱いやすいため、まずJSON-LDで考えるのが現実的です。
FAQ構造化データはまだ使えますか?
FAQPage自体は存在しますが、GoogleのFAQリッチリザルトは政府機関または保健衛生関連の有名で権威あるサイト向けに限定されています。一般的なBtoBサイトでは、検索結果で目立たせる目的ではなく、ページ内のFAQを整理する補助として慎重に扱うのが現実的です。
構造化データはAI検索対策になりますか?
AI検索専用の魔法ではありません。GoogleのAI機能に関する公式ドキュメントでも、従来のSEOのベストプラクティスが有効であることが説明されています。構造化データは、AI検索だけを狙うものではなく、ページ情報を整理する基礎整備として扱うのがよいです。
Search Consoleに構造化データのレポートが出ないのはなぜですか?
Googleがサポートするリッチリザルト対象の構造化データが検出されていない、対象ページが少ない、まだクロールされていない、またはレポート対象ではない種類を使っている可能性があります。まずリッチリザルトテストとURL検査で代表ページを確認してください。
構造化データだけ外部に依頼してもよいですか?
可能ですが、実務上はページ設計、本文、著者情報、会社情報、パンくず、Search Console、CTAまで一緒に確認した方が効果的です。構造化データだけを追加しても、ページの目的や導線が曖昧だと改善判断がしにくくなります。
参考にした公式情報
- Google 検索セントラル 構造化データの仕組み
- Google 検索でサポートされている構造化データ
- Google 構造化データに関する一般的なガイドライン
- Google FAQPage構造化データ
- Google AI機能とウェブサイト
- リッチリザルトテスト
- schema.org
アズくんからのお知らせ
関連サービスとして、SEOの支援範囲も確認できます。
集客や問い合わせにつながる施策の優先順位が決まらない場合は、概要ページをご確認ください。
SEOサービスの概要を見る
デジタルマーケティング相談窓口
Web広告やSEOの改善余地を、まずは無料で確認しませんか?
集客をもっと増やしたい、新規施策の見積もりが欲しい、今の業者からの切り替えを考えている場合は、現状の課題から相談できます。
- 集客をもっと増やすにはどうしたらいい?
- 新規施策を行いたいが見積もりが欲しい
- 今の業者からの切り替えを考えている
無料診断を相談する