
インデックスされない原因と対処法:Search Consoleで確認する手順
記事やサービスページを公開したのに、Google検索に出てこない。Search Consoleを見ると「検出 - インデックス未登録」「クロール済み - インデックス未登録」「代替ページ」などが並んでいて、どこから直せばよいか分からない。
この状態で焦ってインデックス登録リクエストを何度も押したくなる気持ちは自然です。ただ、実務では、リクエストを繰り返す前に確認すべきことがあります。なぜなら、インデックスされない原因は1つではなく、URLが見つかっていない、クロールできない、登録を拒否している、正規URLが別にある、ページの品質や重複で登録されていないなど、工程ごとに分かれるからです。
結論から言うと、インデックスされない時は、まずSearch ConsoleのURL検査で個別URLを確認し、次に「発見」「取得」「登録可否」「正規化」「品質」「内部リンク」の順番で原因を切り分けます。登録リクエストは原因を直した後の再確認であり、原因を直さずに押し続けても根本解決にはなりません。
特にBtoBサイトでは、未登録URLをすべて同じ重みで見る必要はありません。サービスページ、事例ページ、比較記事、問い合わせ導線に近い記事、広告LPと接続しているページなど、問い合わせや商談に近いURLから優先して確認します。タグ一覧や検索結果ページ、重複しやすいアーカイブが未登録でも、事業上は問題ない場合があります。
この記事では、Googleにインデックスされない時の原因、Search Consoleでの確認手順、検出・クロール済み未登録の違い、noindex・robots.txt・canonicalの確認、サイトマップと内部リンク、品質や重複の見直し、重要URLから優先する考え方まで整理します。
補足ボックス|この記事でわかること
- インデックスされない時に最初に見るべき場所
- Search ConsoleのURL検査で確認する項目
- 「検出」「クロール済み」「noindex」「代替ページ」の読み分け
- noindex、robots.txt、canonical、HTTPステータスの確認方法
- サイトマップと内部リンクで重要URLを見つけてもらう考え方
- 品質不足や重複による未登録への対処
- BtoBサイトで優先して対応すべきURL
- 自社で確認する範囲と外部に相談する範囲
補足ボックス終了
インデックスされない時は状態名だけで判断しない
インデックスされないページを見つけた時に、最初に避けたいのは、Search Consoleの状態名だけで原因を決めつけることです。「クロール済み - インデックス未登録」と表示されているから品質が低い、「検出 - インデックス未登録」と表示されているから登録リクエストを押せばよい、と単純に考えると、対処を間違えます。
Google検索にページが出るまでには、URLの発見、クロール、レンダリング、正規化、インデックス登録、ランキングという流れがあります。Google公式のクロールとインデックス登録に関するドキュメントでも、robots.txt、サイトマップ、canonical、noindexなど、複数の管理項目が整理されています。
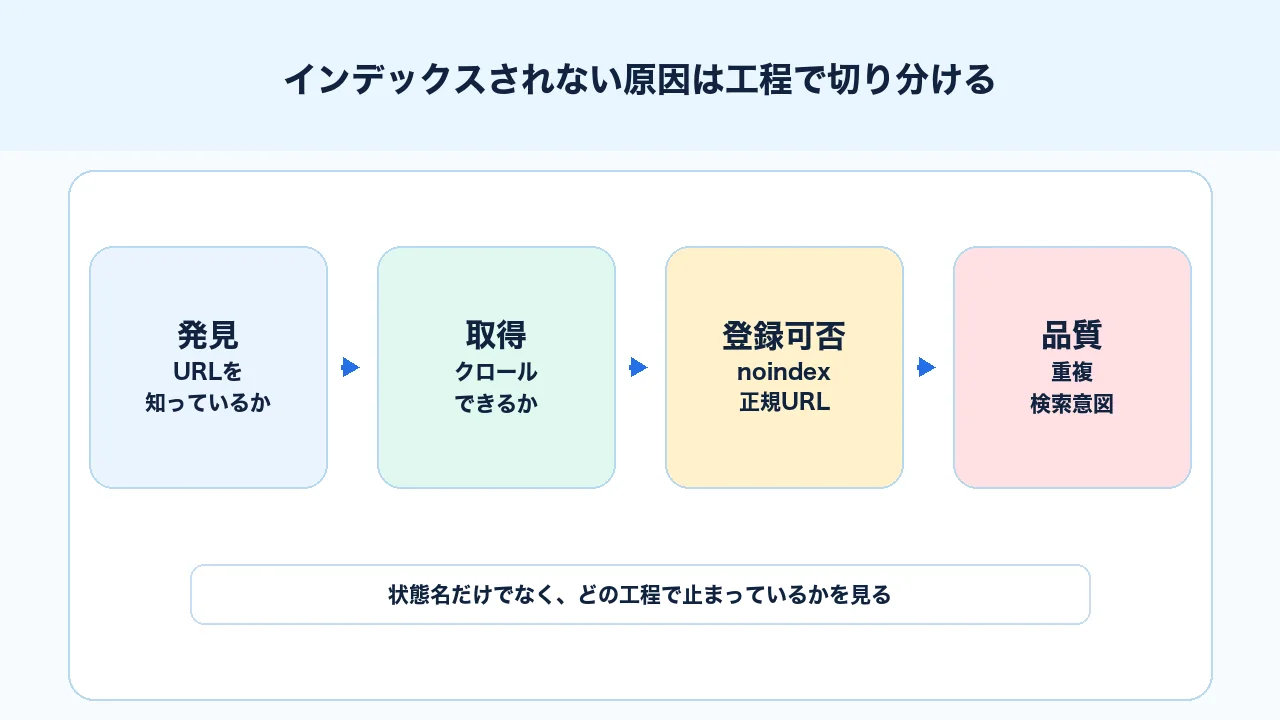
つまり、インデックスされない原因は、次のように分けて考える必要があります。
| 工程 | 何を見るか | よくある原因 |
|---|---|---|
| 発見 | GoogleがURLを知っているか | 内部リンク不足、サイトマップ未送信 |
| 取得 | Googlebotがページを取得できるか | robotsブロック、HTTPエラー、サーバー負荷 |
| 登録可否 | インデックス登録を許可しているか | noindex、X-Robots-Tag |
| 正規化 | どのURLを代表として扱うか | canonical不一致、重複URL |
| 品質 | 検索結果に出す価値があるか | 薄い内容、重複、検索意図ずれ |
| 導線 | サイト内で重要ページとして扱われているか | 孤立ページ、内部リンク不足 |
インデックスされない問題は、技術設定だけでも、記事品質だけでもありません。 設定の問題と内容の問題が同時に起きていることもあります。たとえば、サービスページはnoindexではないものの、関連する記事からリンクされておらず、サイトマップにも含まれていない場合があります。逆に、サイトマップや内部リンクは問題ないのに、内容が既存記事とほとんど同じで登録されにくい場合もあります。
綱脇耕輔の実務見解として、BtoBサイトで最初にやるべきことは、未登録URLをすべて一覧化することではありません。まず「検索に出したい重要URL」を決めます。サービスページ、事例ページ、比較記事、問い合わせに近い記事など、事業への影響が大きいURLから見る方が、対応の優先順位を誤りにくくなります。
状態名は入口であり、原因そのものではありません。 Search Consoleの表示を見たら、そのURLがサイト内でどんな役割を持つのか、技術設定はどうなっているか、内容は検索意図に答えているかまで確認してください。
Search ConsoleのURL検査でまず個別URLを確認する
インデックスされないページを確認する時は、まずSearch ConsoleのURL検査を使います。URL検査ツールは、個別URLについて、Googleに登録されているか、クロールされた日時、Googleが選択した正規URL、noindexなどの登録阻害要因を確認するための機能です。Google公式ヘルプのURL検査ツールでも、ページのインデックス登録状態やURLの検査方法が案内されています。
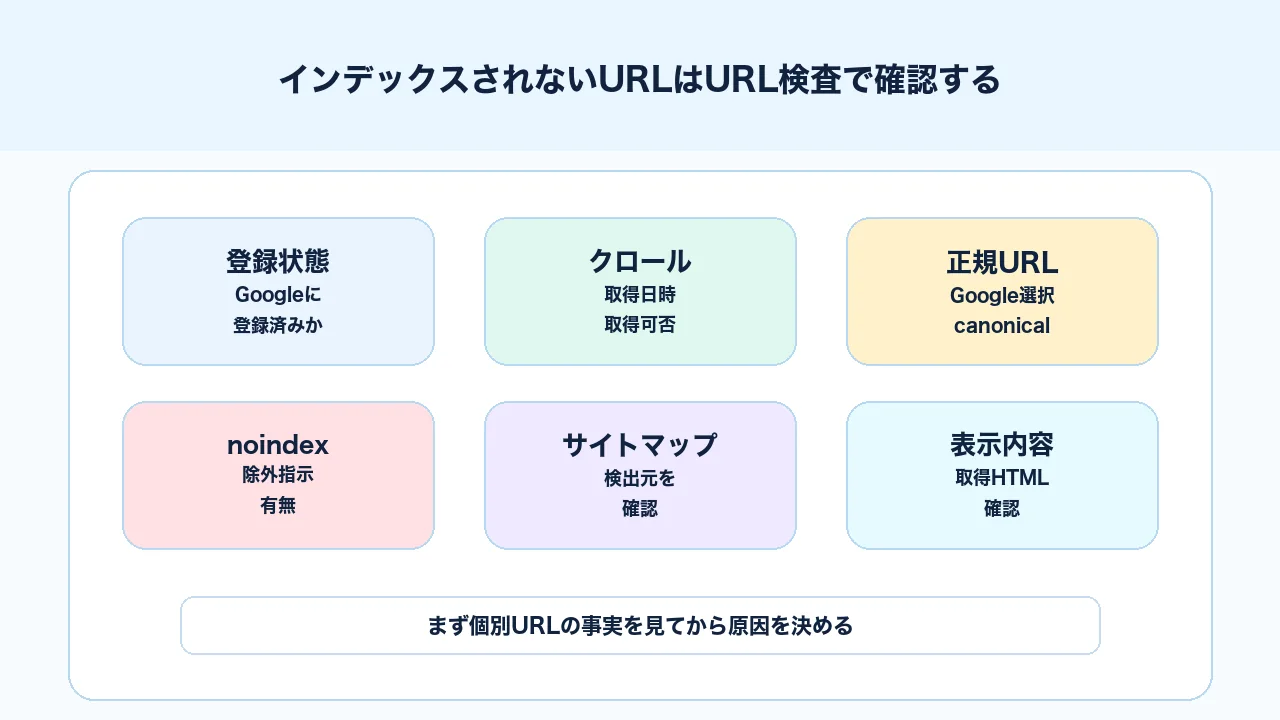
URL検査で見るべき項目は、次の通りです。
| 確認項目 | 見る理由 | 判断の例 |
|---|---|---|
| Googleに登録されていますか | 検索結果に出る候補か確認する | 登録済みなら順位・CTR確認へ進む |
| ページの取得 | Googlebotが取得できたか確認する | 取得不可なら技術問題を確認 |
| 最終クロール日時 | いつ確認されたか見る | 古い場合は更新反映待ちの可能性 |
| Googleが選択した正規URL | 別URLが代表になっていないか見る | 意図しないURLならcanonicalや重複を確認 |
| noindex | 除外指示がないか確認する | 誤設定なら解除 |
| サイトマップ | URLがサイトマップで検出されたか見る | 検出されていなければサイトマップ確認 |
URL検査は、1URLの事実を確認するためのものです。ページレポートで大量の未登録URLが表示されていても、まず代表的なURLを数件選び、URL検査で状態を確認します。同じテンプレート、同じカテゴリ、同じ記事種別で同じ問題が出ているなら、個別ページではなくサイト構造やCMS設定に原因がある可能性があります。
URL検査で見るべきなのは、登録済みか未登録かだけではありません。 Googleが選択した正規URL、クロール日時、検出元、noindex、ページ取得可否まで見ます。これらを見ずに「インデックス登録をリクエスト」だけを押しても、原因が残っている限り改善しません。
Google公式のGoogle検索で自分のページが見つからない場合でも、ページがGoogle検索に表示されない場合は、サイト全体が登録されているか、個別ページが登録されているか、重複や正規ページの扱いを確認する考え方が示されています。
実務では、URL検査の結果を次のようにメモすると原因を整理しやすくなります。
| URL | 状態 | Google選択正規URL | noindex | 内部リンク | 次の対応 |
|---|---|---|---|---|---|
| サービスA | 未登録 | 自URL | なし | 少ない | 関連記事からリンク追加 |
| 記事B | クロール済み未登録 | 別記事 | なし | あり | 重複整理・統合検討 |
| 事例C | noindex | 自URL | あり | あり | 誤設定なら解除 |
この表のように、状態と原因候補を分けることで、登録リクエスト、設定修正、リライト、統合、内部リンク追加のどれを行うべきか判断しやすくなります。
検出・クロール済み・インデックス未登録を分けて読む

Search Consoleで混同しやすいのが、「検出 - インデックス未登録」と「クロール済み - インデックス未登録」です。どちらも検索結果に出ていない状態ですが、止まっている工程が違います。
「検出 - インデックス未登録」は、GoogleがURLを知っているものの、まだクロールしていない、またはクロール処理に進んでいない状態です。URLは発見されているため、サイトマップやリンクなどでGoogleに知られている可能性があります。ただし、クロールの優先順位が低い、サイト内で重要度が低く見える、URL数が多すぎる、サーバー負荷が懸念されるなどの理由で、すぐに取得されないことがあります。
「クロール済み - インデックス未登録」は、Googlebotがページを取得したものの、インデックス登録されていない状態です。ここでは、技術的には取得できているため、次に見るべきはnoindex、canonical、重複、品質、検索意図との一致、サイト内での役割です。
違いを整理すると、次のようになります。
| 状態 | 起きていること | 主な確認 |
|---|---|---|
| 検出 - インデックス未登録 | URLは知られているが未クロール | 内部リンク、サイトマップ、重要度 |
| クロール済み - インデックス未登録 | 取得されたが登録されていない | 品質、重複、canonical、noindex |
| 代替ページ | 別URLが正規と判断されている | canonical、重複、URL設計 |
| noindexにより除外 | 登録しない指示がある | meta robots、X-Robots-Tag |
| 登録済み | 検索候補に入っている | 順位、CTR、検索意図 |
検出とクロール済みを分けるだけで、対処の順番は大きく変わります。 検出の段階なら、内部リンクやサイトマップ、サイト内の重要度を見ます。クロール済み未登録なら、取得後に登録されなかった理由を見ます。
ここで大切なのは、未登録URLをゼロにすることを目的にしないことです。タグ一覧、検索結果ページ、重複するパラメータURL、ページネーションの2ページ目以降など、検索結果に出す必要が低いURLが未登録になるのは自然な場合があります。
一方で、サービスページ、事例ページ、主要なSEO記事、比較記事、問い合わせ導線に近いページが未登録なら、優先的に確認します。未登録を問題にするかどうかは、URLの事業上の役割で決めます。 Search Consoleの件数だけを見て焦るのではなく、重要URLが検索候補に入っているかを見てください。
noindex・robots.txt・canonicalの誤設定を確認する
インデックスされない時に最初に確認したい技術設定は、noindex、robots.txt、canonical、HTTPステータスです。これらはページ品質の改善よりも先に確認します。なぜなら、重要ページが誤って除外されている場合、どれだけ良い記事を書いても検索結果に出ないからです。
noindexは、ページをインデックス登録しないように検索エンジンへ伝える指定です。Google公式のnoindexで検索インデックス登録をブロックする方法では、metaタグまたはHTTPレスポンスヘッダーでnoindexを設定できること、またnoindexを認識するにはGooglebotがページへアクセスできる必要があることが説明されています。
robots.txtは、クローラーのアクセスを制御するためのファイルです。Google公式のrobots.txtの概要では、robots.txtは主にクロール制御のためのものであり、Googleにページを表示させないための仕組みとしてはnoindexやパスワード保護を使う考え方が示されています。
canonicalは、重複または類似したURLの中で、どのURLを代表として扱ってほしいかを示す指定です。Google公式の重複URLを統合する方法では、canonical、リダイレクト、サイトマップなどによる正規化の考え方が説明されています。
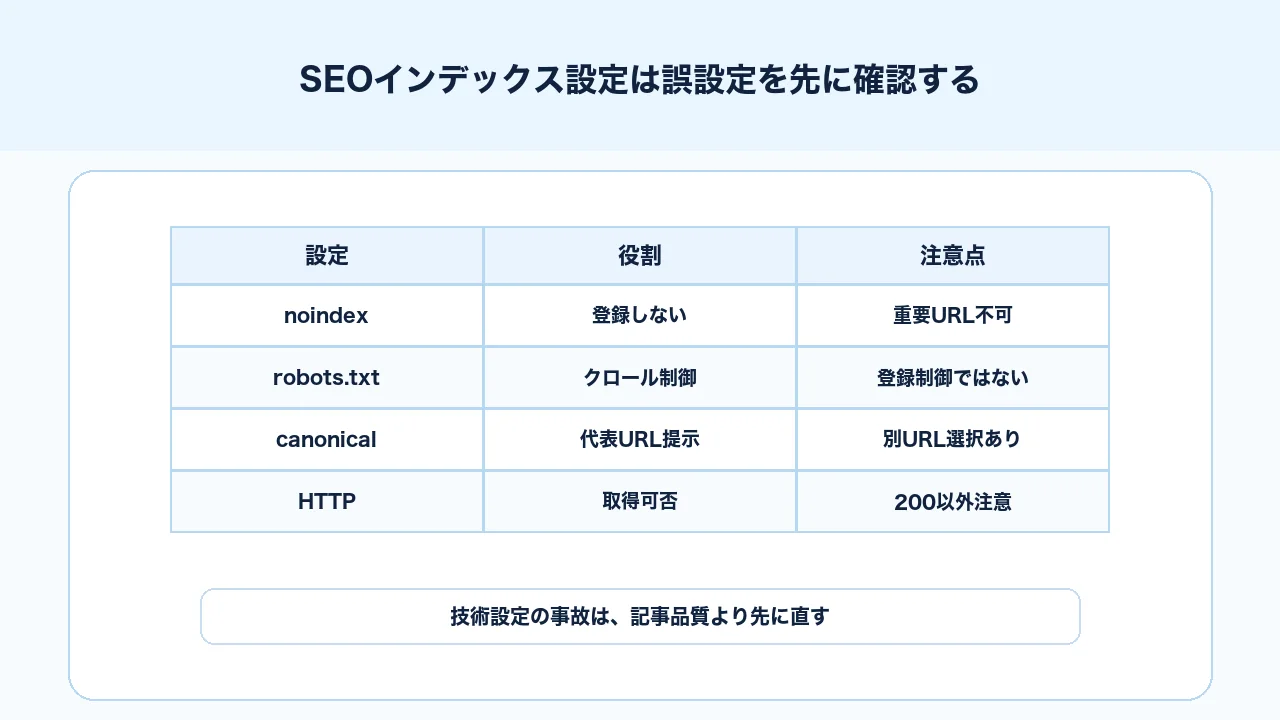
| 設定 | 役割 | よくある失敗 |
|---|---|---|
| noindex | インデックス登録しないように伝える | 検証環境の設定が本番に残る |
| X-Robots-Tag | HTTPヘッダーで登録制御する | PDFや画像、CMS出力で見落とす |
| robots.txt | クロールを制御する | 登録制御と誤解する |
| canonical | 代表URLを示す | 別URLへ誤って向ける |
| HTTPステータス | ページ取得可否を示す | 404、500、リダイレクト連鎖 |
重要ページにnoindexを残したまま公開したり、robots.txtで重要ディレクトリをブロックしたり、canonicalを別URLへ誤って向けたりすると、検索流入の入口を止める可能性があります。サイトリニューアル、CMS移行、テンプレート変更、ステージング公開後は必ず確認してください。
Google公式のGoogle検索の技術要件でも、Googleがインデックス登録するにはページが正常なHTTP 200で配信され、インデックス可能なコンテンツがあることが前提として説明されています。URL検査では、ページ取得可否やインデックス登録の可否を確認できます。
綱脇耕輔の実務見解として、インデックスされない相談でよくあるのは、記事内容の問題だと思っていたら、実際にはテンプレート側のnoindexやcanonical設定だったというケースです。本文の改善より前に、技術設定で検索対象から外していないかを確認するだけで、原因の切り分けがかなり進みます。
内部リンクとサイトマップで重要URLを発見しやすくする
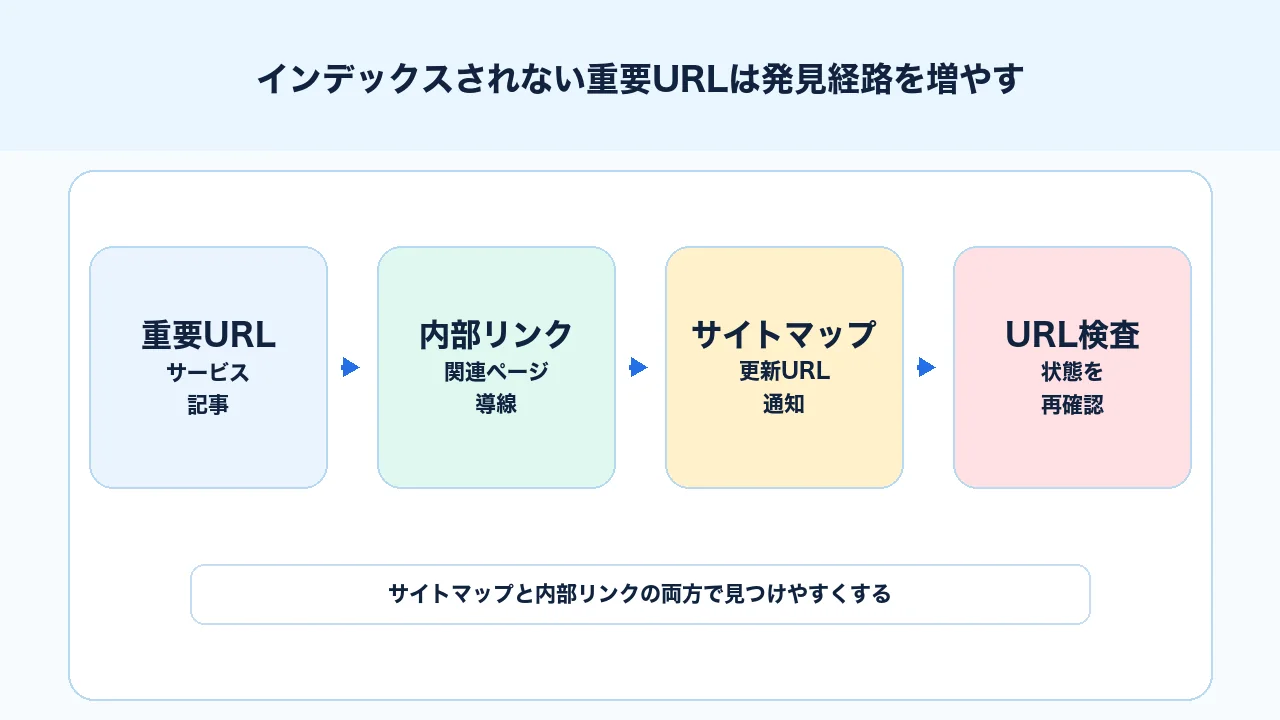
インデックスされないページが「検出 - インデックス未登録」に多く含まれている場合、GoogleがURLを知っていても、優先的にクロールするほど重要だと判断しにくい状態かもしれません。その時に見るのが、内部リンクとサイトマップです。
サイトマップは、Googleに重要URLや更新URLを知らせるための補助です。Google公式のサイトマップの作成と送信でも、サイトマップを使ってページを知らせる方法が説明されています。ただし、サイトマップに入れたからといって、クロールやインデックス登録が保証されるわけではありません。
内部リンクは、サイト内で重要ページへ読者とGooglebotを案内する導線です。重要ページがサイト内のどこからもリンクされていない、カテゴリ一覧から遠い、関連記事からつながっていない場合、GoogleにとってもそのURLの重要度が伝わりにくくなります。
サイトマップは通知、内部リンクは重要度と導線を伝える役割です。 どちらか一方だけではなく、両方を見ます。
確認したいポイントは次の通りです。
| 確認項目 | 見ること | 改善例 |
|---|---|---|
| XMLサイトマップ | 重要な正規URLだけが含まれているか | noindex、404、リダイレクト元を除外 |
| 内部リンク | 重要URLへ自然なリンクがあるか | 関連記事、カテゴリ、親記事から追加 |
| 孤立ページ | どこからもリンクされていないURLがないか | 一覧、パンくず、関連記事で接続 |
| 更新導線 | 新規・更新ページが伝わるか | サイトマップ更新、記事内リンク追加 |
| CV導線 | 読者が次に進めるか | サービスページや相談導線へ接続 |
BtoBサイトでは、記事を公開しているのにサービスページへつながっていないことがあります。この場合、記事単体はインデックスされても、問い合わせに近いページへ読者が進みにくくなります。インデックス確認をする時も、単にページ単体が登録されているかではなく、記事群、サービスページ、事例ページ、問い合わせ導線のつながりを見ることが大切です。
重要URLは、サイトマップに入れるだけでなく、サイト内で自然にリンクされている状態にします。 検索に出したいページほど、関連する記事やカテゴリから内部リンクを集めてください。
品質・重複・検索意図の不足も未登録の原因になる
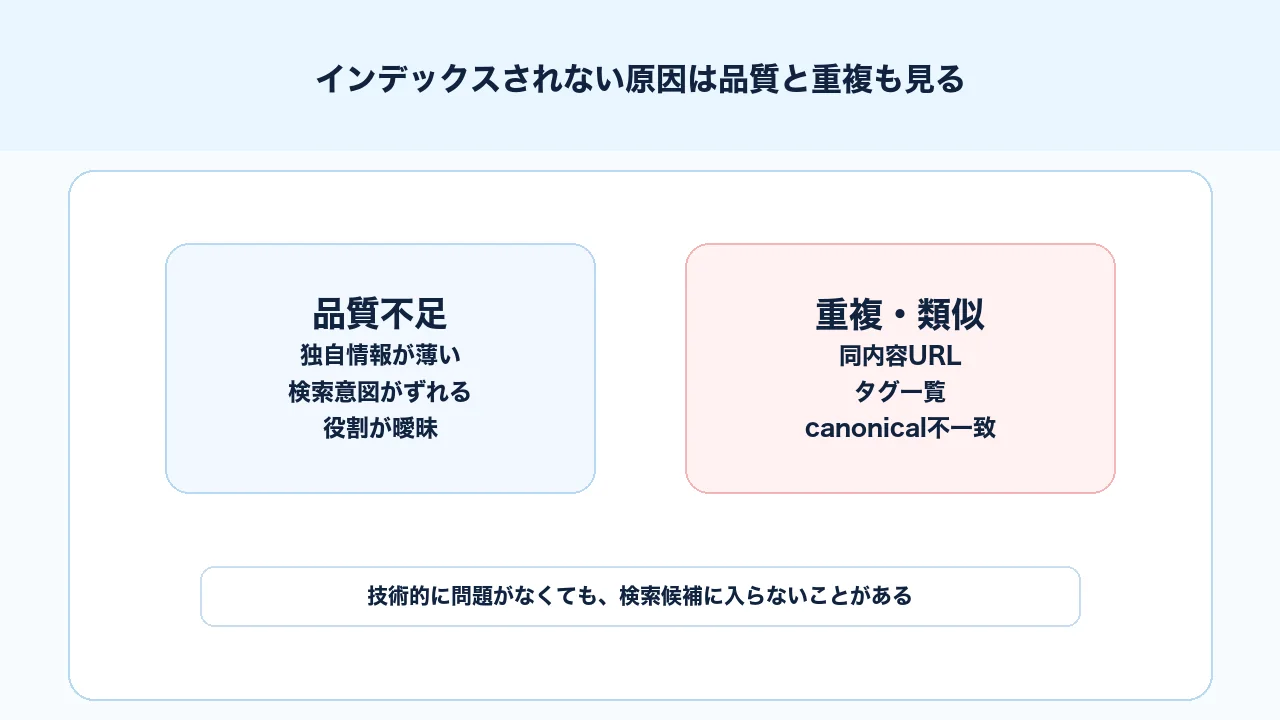
技術設定に問題がなく、Googlebotがクロールできているのにインデックス登録されない場合、品質、重複、検索意図とのずれを確認します。これは、単に文字数を増やせばよいという話ではありません。
Googleは、すべてのクロール済みページを検索結果に出すわけではありません。類似したページが多い、内容が薄い、既存記事と役割が重複している、検索意図に対する答えが浅い、読者が次に判断できる材料がない、といった場合、検索結果に出す候補として扱われにくくなることがあります。
品質を見る時は、次の観点で確認します。
| 観点 | 確認すること | 改善方向 |
|---|---|---|
| 検索意図 | 読者の疑問に答えているか | 冒頭で結論と対象読者を明確化 |
| 独自価値 | 他ページにない判断材料があるか | チェックリスト、比較表、実務見解を追加 |
| 重複 | 既存記事と役割が重なっていないか | 統合、リライト、canonical整理 |
| 導線 | 読者が次に進めるか | 関連記事、サービスページ、CTAを設置 |
| 情報鮮度 | 古い仕様や画面説明でないか | 公式情報と現画面に合わせて更新 |
インデックスされないページは、技術的に問題がなくても、検索結果に出す意味が弱いと判断されることがあります。 ここで重要なのは、一般論を増やすことではありません。そのページがサイト内でどんな役割を持ち、読者のどの判断を助けるのかを明確にすることです。
たとえば「SEOとは」という記事と「SEO対策とは」という記事がほぼ同じ内容なら、Googleにとっても読者にとっても役割が重複します。費用記事、会社選び記事、やり方記事、リライト記事、技術SEO記事など、記事ごとの役割を分ける必要があります。
綱脇耕輔の実務見解として、未登録ページのリライトでは「文字量を増やす」よりも「役割をはっきりさせる」方が重要です。読者がこの記事を読んだ後に何を判断できるのか、どのページへ進むべきなのか、検索意図に対してどの独自情報を出すのかを整理します。
品質改善とは、文章を長くすることではなく、検索意図と記事の役割を一致させることです。 インデックスされない記事を見直す時は、まず既存記事との重複と、読者の判断材料の不足を確認してください。
BtoBサイトでは重要URLから優先して対処する
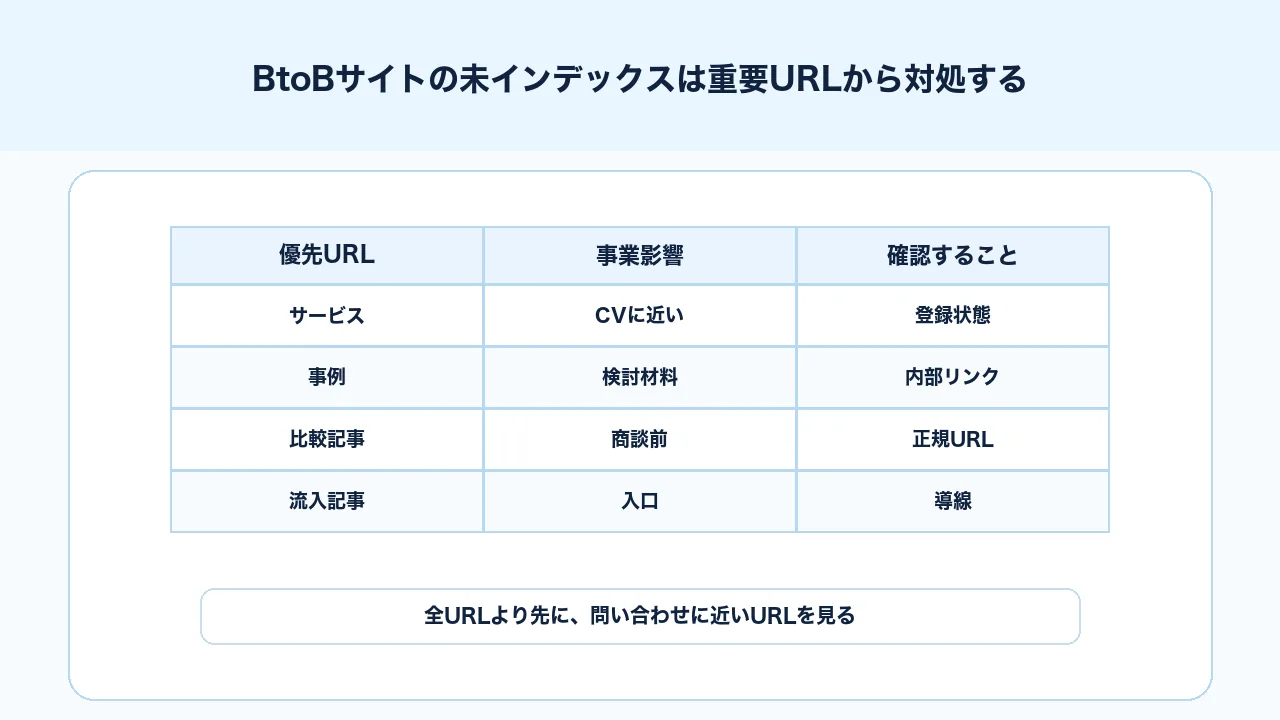
インデックスされないURLが多い時に、すべてを同じ優先度で直そうとすると、工数だけが増えます。BtoBサイトでは、問い合わせや商談に近いURLから優先します。
優先度を決める時は、次の4つを見ます。
1. CVに近いか 2. 検索流入の入口になり得るか 3. 商談前の判断材料になるか 4. そのURLが未登録だと事業上の機会損失が大きいか
たとえば、サービスページ、料金ページ、事例ページ、比較記事、指名検索に近い記事、問い合わせ導線へつながる記事は優先度が高いです。一方、タグ一覧の2ページ目、古いアーカイブ、検索結果ページ、パラメータURL、内容が重複する低重要ページは、未登録でも問題ない場合があります。
Palcoolでは、未インデックスの優先度を考える時、次のような簡易スコアで見ることがあります。これは試算例であり、すべてのサイトにそのまま当てはまるものではありません。
| 観点 | 0点 | 1点 | 2点 |
|---|---|---|---|
| CV距離 | 遠い | 関連あり | 近い |
| 事業影響 | 小さい | 中程度 | 大きい |
| 検索需要 | ほぼない | あり | 高い |
| 代替ページ | ある | 一部ある | ない |
| 技術リスク | 不明 | 一部あり | 明確 |
合計点が高いURLから、URL検査、noindex、canonical、内部リンク、サイトマップ、品質、重複を確認します。未登録URLの件数ではなく、事業影響の大きいURLを優先することが重要です。
たとえば、問い合わせにつながるサービスページが未登録なら、1ページでも優先度は高いです。逆に、タグ一覧の重複URLが100件未登録でも、検索に出す必要がなければ慌てて対応しなくてよい場合があります。
BtoBのインデックス改善は、件数削減ではなく、重要URLを検索対象に戻す作業です。まずは「検索に出したいURLリスト」を作り、重要度の高い順に確認してください。
原因別に対処法を決める
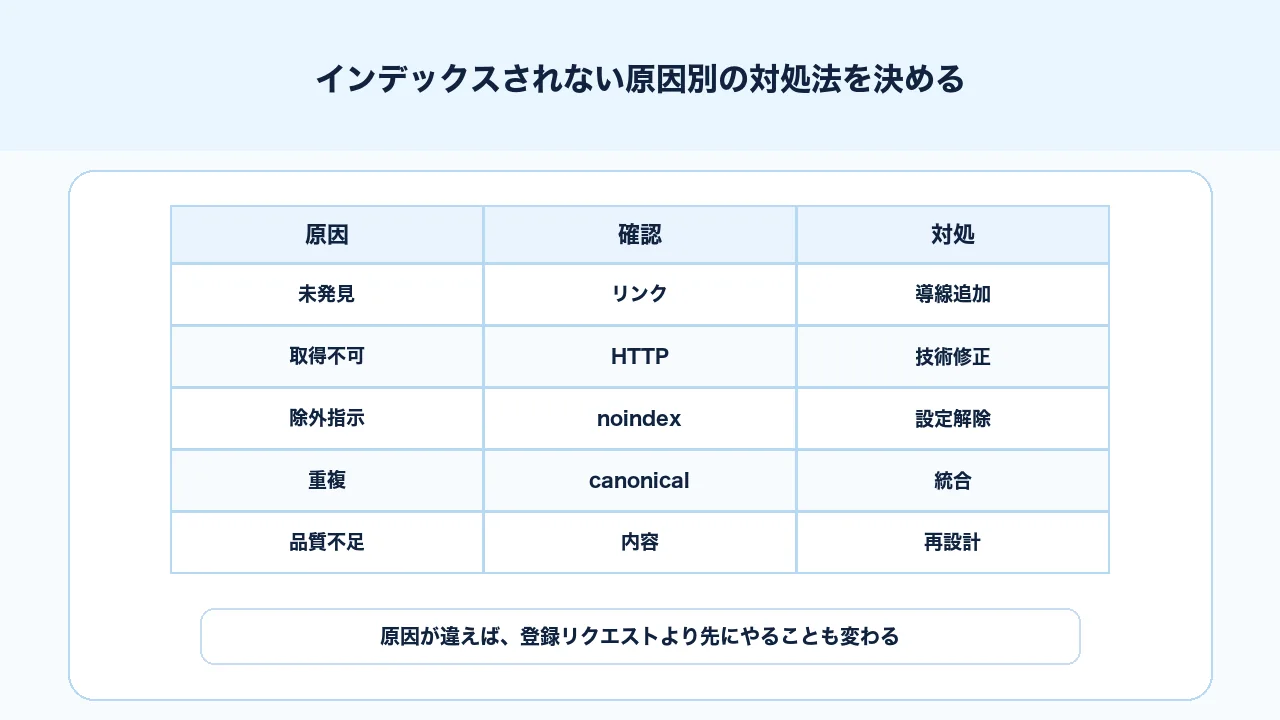
インデックスされない原因は複数あるため、対処法も原因ごとに変わります。登録リクエスト、内部リンク追加、noindex解除、canonical修正、リライト、統合、削除、noindex維持など、選択肢を分けて考えます。
原因別の対応を整理すると、次のようになります。
| 原因 | 確認すること | 対処法 |
|---|---|---|
| URLが発見されていない | 内部リンク、サイトマップ | 関連ページからリンク、サイトマップ追加 |
| クロールできない | HTTPステータス、robots.txt | サーバー、制御、リダイレクト修正 |
| noindexがある | meta robots、X-Robots-Tag | 意図しない場合は解除 |
| 正規URLが別 | canonical、重複URL | 統合、canonical修正、リンク先整理 |
| 品質が弱い | 検索意図、独自価値 | 再設計、追記、見出し改善 |
| 重複している | 既存記事、類似ページ | 統合、リライト、noindex判断 |
| 孤立している | 内部リンク、カテゴリ | 親記事や関連記事から接続 |
この表で見ると分かるように、インデックス登録リクエストは万能ではありません。noindexが残っていれば解除が必要です。canonicalが別URLを指していれば正規化の整理が必要です。品質や重複が原因なら、本文や記事の役割を見直す必要があります。
Google公式のクロール・インデックス登録リクエストでは、URL検査ツールやサイトマップによって再クロールをリクエストする方法が説明されています。ただし、リクエストは処理のきっかけであり、インデックス登録を保証するものではありません。
原因を直してから、再クロールやインデックス登録リクエストを行うのが基本です。 原因を残したままリクエストだけを繰り返すと、作業している感覚はありますが、成果につながりにくくなります。
実務では、重要URLごとに次のようなステータスを付けると管理しやすくなります。
| URL | 原因候補 | 対応 | 担当 | 再確認日 |
|---|---|---|---|---|
| サービスページ | noindex | 解除 | 制作 | 3日後 |
| 比較記事 | 重複 | 統合判断 | SEO | 1週間後 |
| 事例ページ | 内部リンク不足 | 関連記事からリンク | 編集 | 1週間後 |
| 費用記事 | 品質不足 | 見積もり表を追加 | 編集 | 2週間後 |
このように、原因と対応を分けると、改善後の確認もしやすくなります。
登録リクエストを繰り返す前に確認する
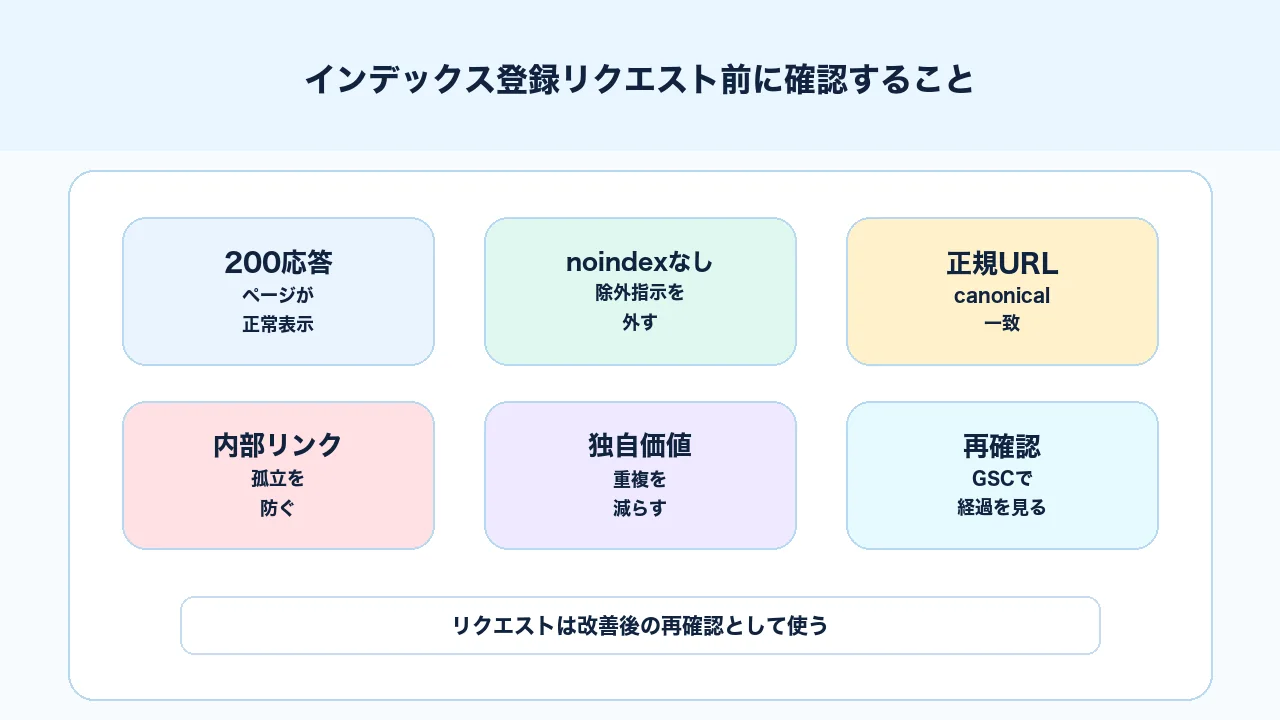
インデックスされない時に、すぐ登録リクエストを押したくなるのは自然です。ただし、Search Consoleのリクエストは「原因を直した後に再確認してもらう」ために使うものです。原因が残ったままでは、何度押しても登録されないことがあります。
登録リクエスト前のチェックリストは次の通りです。
| チェック | 見ること | OKの目安 |
|---|---|---|
| HTTPステータス | 200で返っているか | 404、500、長いリダイレクトがない |
| noindex | meta robotsやヘッダー | 検索に出したいURLはnoindexなし |
| robots.txt | クロール制御 | 重要URLがブロックされていない |
| canonical | 正規URL | 自URLまたは意図したURLを示している |
| 内部リンク | 発見経路 | 関連ページから自然にリンクされている |
| サイトマップ | 検出補助 | 正規URLとして含まれている |
| 内容 | 検索意図 | 独自の判断材料がある |
| 重複 | 既存記事との重なり | 役割が分かれている |
登録リクエストは、チェックリストを通過した後に使う再確認の手段です。特に重要URLでは、技術設定と内容の両方を確認してからリクエストします。
また、リクエスト後すぐに反映されるとは限りません。数日で変わることもあれば、しばらく変わらないこともあります。Search ConsoleのURL検査、ページレポート、サイトマップ、検索パフォーマンスを一定期間見ながら確認します。
BtoBサイトの場合は、Search Consoleだけでなく、GA4や問い合わせデータも見ます。重要記事がインデックスされ、表示回数が出始めたら、クリック、CTR、問い合わせ導線への遷移、フォーム到達などを確認します。インデックスはゴールではなく、検索流入と問い合わせ導線を見るための入口です。
綱脇耕輔の実務見解として、登録リクエストに時間を使いすぎるより、重要URLの役割、内部リンク、検索意図、サービス導線を整える方が成果につながることが多いです。リクエストは最後の確認として使い、先に原因を取り除くことを優先してください。
自社で対応する範囲と外部に相談する範囲
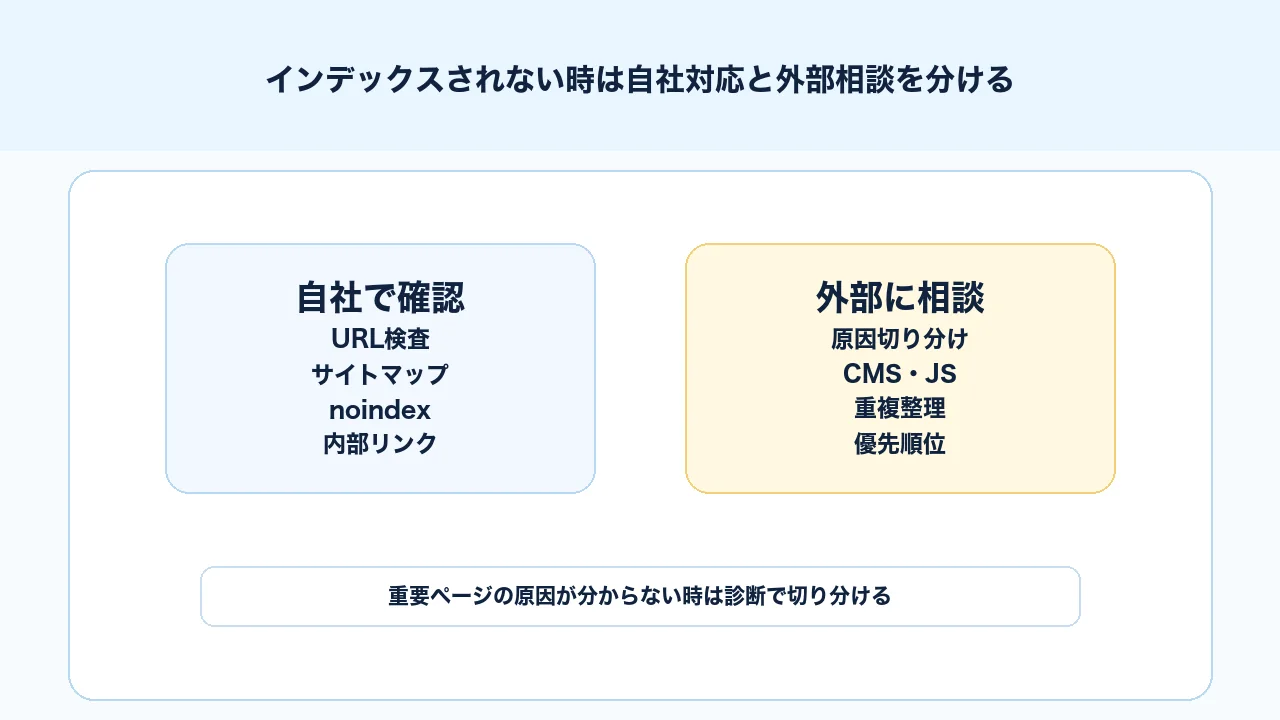
インデックスされない問題は、自社で確認できる範囲と、外部に相談した方がよい範囲を分けて考えます。すべてを外部に任せる必要はありませんが、原因が複数絡む場合は、早めに切り分けた方が対応が進みます。
自社で確認しやすいのは、Search ConsoleのURL検査、ページレポート、サイトマップ、noindexの有無、内部リンク、記事の重複、重要URLリストです。CMSの管理画面で設定を確認できる場合は、noindexやcanonicalの状態も見られます。
一方で、外部に相談した方がよいのは、CMSやテンプレート単位でnoindexやcanonicalが出ている、JavaScriptレンダリングが絡む、robots.txtやサーバー設定が複雑、リニューアル後に大量のURLが未登録になった、重要ページの原因が分からない、記事群の重複と内部リンクを整理したい、といったケースです。
| 自社で確認 | 外部に相談 |
|---|---|
| URL検査で状態を見る | 状態ごとの原因を横断的に切り分ける |
| noindexの有無を確認する | CMSテンプレートやヘッダー出力を確認する |
| サイトマップを確認する | URL設計、canonical、リダイレクトを整理する |
| 内部リンクを追加する | 記事群とサービス導線を再設計する |
| 重複記事を洗い出す | 統合、リライト、noindex判断を設計する |
相談前に準備するとよいのは、検索に出したい重要URLのリストです。 未登録URLをすべて持ち込むより、サービスページ、事例ページ、主要記事、比較記事、問い合わせ導線に近い記事を10〜30URLほど整理すると、診断の精度が上がります。
Palcoolでは、SEO診断やデジタルマーケティング支援の中で、Search Console、GA4、広告データ、問い合わせ導線を見ながら、検索流入から商談につながるURLを優先して確認します。単にインデックス登録数を増やすのではなく、事業上重要なURLが検索対象に入っているかを見ます。
もし重要ページがインデックスされない、原因が設定なのか品質なのか分からない、Search Consoleの状態を見ても対応順位が決められない場合は、まず重要URLを整理して相談するのが現実的です。
まとめ:重要ページから原因を切り分ける
インデックスされない時は、焦って登録リクエストを繰り返す前に、原因を工程ごとに切り分けます。URLが発見されているか、クロールできるか、noindexやrobots.txtで止めていないか、canonicalは意図通りか、品質や重複に問題がないか、内部リンクやサイトマップで重要URLとして扱われているかを確認します。
Search Consoleでは、まずURL検査で個別URLを見ます。次にページレポートで同じ状態のURLが広がっていないかを確認します。検出とクロール済み未登録では原因も対処も違うため、状態名を混同しないことが大切です。
BtoBサイトでは、未登録件数を減らすことより、問い合わせや商談に近い重要URLを検索対象に戻すことが優先です。 サービスページ、事例ページ、比較記事、主要記事から確認し、事業影響の大きいURLに絞って対応しましょう。
インデックスはSEOのゴールではありません。検索結果に出る候補へ入った後に、順位、CTR、記事の回遊、サービス導線、問い合わせまで確認して初めて、SEO施策としての改善が見えてきます。
よくある質問
インデックスされない時は何を最初に確認すればよいですか?
まずSearch ConsoleのURL検査で、対象URLがGoogleに登録されているか、クロールされたか、noindexがあるか、Googleが選択した正規URLはどれかを確認します。その後、内部リンク、サイトマップ、品質、重複を確認します。
検出 - インデックス未登録とクロール済み - インデックス未登録は何が違いますか?
検出 - インデックス未登録は、GoogleがURLを知っているものの、まだクロールしていない状態です。クロール済み - インデックス未登録は、Googlebotがページを取得したものの、インデックス登録されていない状態です。前者は発見経路や重要度、後者は品質、重複、canonical、noindexなどを確認します。
インデックス登録リクエストを押せば解決しますか?
必ず解決するわけではありません。リクエストは再クロールや再確認のきっかけとして使うものです。noindex、robots.txt、canonical、品質、重複、内部リンク不足などの原因が残っている場合は、先に原因を直す必要があります。
noindexとrobots.txtはどちらを見ればよいですか?
両方を確認します。noindexはインデックス登録しないように伝える指定です。robots.txtはクロールを制御するためのものです。Googleにページを表示させたくない場合は、robots.txtだけに頼らずnoindexやパスワード保護を検討します。検索に出したい重要URLでは、noindexやrobotsブロックがないか必ず確認します。
サイトマップに入れていればインデックスされますか?
サイトマップはURLを発見しやすくする補助であり、インデックス登録を保証するものではありません。重要URLはサイトマップに入れるだけでなく、内部リンク、正規URL、ページ品質、検索意図との一致も確認します。
インデックスされない記事は削除した方がよいですか?
すぐ削除する必要はありません。まず、その記事が検索に出すべきURLかを判断します。重要な記事なら、noindex、canonical、内部リンク、品質、重複を確認します。役割が重複している記事なら統合、検索に出す必要がないURLならnoindexや整理を検討します。
参考情報
- URL 検査ツール
- Google 検索で自分のページが見つからない場合
- Google 検索の技術要件
- noindex で検索インデックス登録をブロックする方法
- robots.txt の概要
- 重複 URL を統合する方法
- サイトマップの作成と送信
- クロール・インデックス登録リクエスト
アズくんからのお知らせ
関連サービスとして、SEOの支援範囲も確認できます。
集客や問い合わせにつながる施策の優先順位が決まらない場合は、概要ページをご確認ください。
SEOサービスの概要を見る
デジタルマーケティング相談窓口
Web広告やSEOの改善余地を、まずは無料で確認しませんか?
集客をもっと増やしたい、新規施策の見積もりが欲しい、今の業者からの切り替えを考えている場合は、現状の課題から相談できます。
- 集客をもっと増やすにはどうしたらいい?
- 新規施策を行いたいが見積もりが欲しい
- 今の業者からの切り替えを考えている
無料診断を相談する