
noindexとrobots.txtの違い:検索に出したくないページの制御方法
SEOの技術設定でよく混同されるのが、noindexとrobots.txtです。どちらも検索エンジンに関係する設定ですが、役割はまったく同じではありません。noindexは検索結果に出さないための設定で、robots.txtはクローラーのアクセスを制御するための設定です。
この違いを曖昧にしたまま運用すると、検索に出したい重要ページを誤って止めたり、逆に検索結果に出したくないページがURLだけ残ったりします。特にサイトリニューアル、CMS移行、開発環境から本番公開への切り替え、不要ページの整理では、設定ミスが検索流入に直結します。
結論から言うと、検索結果に出したくないページにはnoindexを使い、クロールさせたくない範囲やクロール負荷を調整したい範囲にはrobots.txtを使います。 ただし、robots.txtでブロックしたページにnoindexを書いても、Googlebotがそのページを読めず、noindexを認識できない可能性があります。
noindexとrobots.txtは、検索に出すかどうかを決める設定と、クロールさせるかどうかを決める設定として分けて考えることが重要です。ここを間違えると、Search Consoleで「robots.txtによりブロック」「noindexにより除外」「インデックス未登録」などが出ても、何を直すべきか判断しにくくなります。
BtoBサイトでは、制御設定を単なる技術用語として扱うのではなく、検索に出すページと出さないページを事業上の役割で管理する必要があります。サービスページ、事例ページ、比較記事、問い合わせ導線に近い記事は検索対象にする。一方で、検証環境、管理画面、重複しやすい一覧、検索結果ページ、低価値な自動生成ページは検索対象から外す。こうした判断を、noindexとrobots.txtの違いを理解したうえで行います。
この記事では、noindexとrobots.txtの違い、それぞれの役割、使い分け、併用時の注意点、CMSや開発環境でよくある誤設定、Search Consoleでの確認方法、BtoBサイトでの管理体制まで整理します。
補足ボックス|この記事でわかること
- noindexとrobots.txtの違い
- noindexを使うべきページ
- robots.txtを使うべき場面
- noindexとrobots.txtを同時に使う時の注意点
- CMS、開発環境、リニューアルで起きやすい誤設定
- Search Consoleで確認すべき場所
- BtoBサイトで検索に出すページと出さないページの管理方法
- 自社で確認する範囲と外部に相談する範囲
補足ボックス終了
noindexとrobots.txtは目的が違う

noindexとrobots.txtは、どちらも検索エンジンの動きに関係します。ただし、目的が違います。noindexは、ページを検索結果に表示させないための設定です。robots.txtは、クローラーがどのURLへアクセスしてよいかを制御するためのファイルです。
Google公式のnoindexを使用してコンテンツをインデックスから除外するでは、noindexはmetaタグまたはHTTPレスポンスヘッダーで指定できること、robots.txtファイルでnoindexルールを指定することはGoogleではサポートされていないことが説明されています。
一方、Google公式のrobots.txtの概要では、robots.txtはクローラーがアクセスしてよいURLを伝えるもので、Googleにウェブページが表示されないようにするための仕組みではないと説明されています。検索結果に表示させないためには、noindexやパスワード保護を使う考え方です。
違いを表にすると、次のようになります。
| 項目 | noindex | robots.txt |
|---|---|---|
| 主な目的 | インデックス登録を防ぐ | クロールを制御する |
| Googlebotのアクセス | ページを読む必要がある | 指定範囲にアクセスしない |
| 検索結果への表示 | 原則として表示させない | URLだけ表示される可能性がある |
| 設定場所 | metaタグ、HTTPヘッダー | ルート直下のrobots.txt |
| 主な用途 | 検索に出したくないページ | クロール負荷や不要URLの巡回制御 |
noindexは検索結果への表示を止めるための設定で、robots.txtはクロールを止めるための設定です。 どちらも「検索エンジン向けの設定」ではありますが、同じ目的で使うものではありません。
綱脇耕輔の実務見解として、混乱が起きるのは「検索に出したくない」と「クローラーに来てほしくない」を同じ意味で扱ってしまう時です。検索結果に出したくないならnoindex。クロール負荷を抑えたい、不要なディレクトリを巡回させたくないならrobots.txt。まず目的を言語化してから設定を選びます。
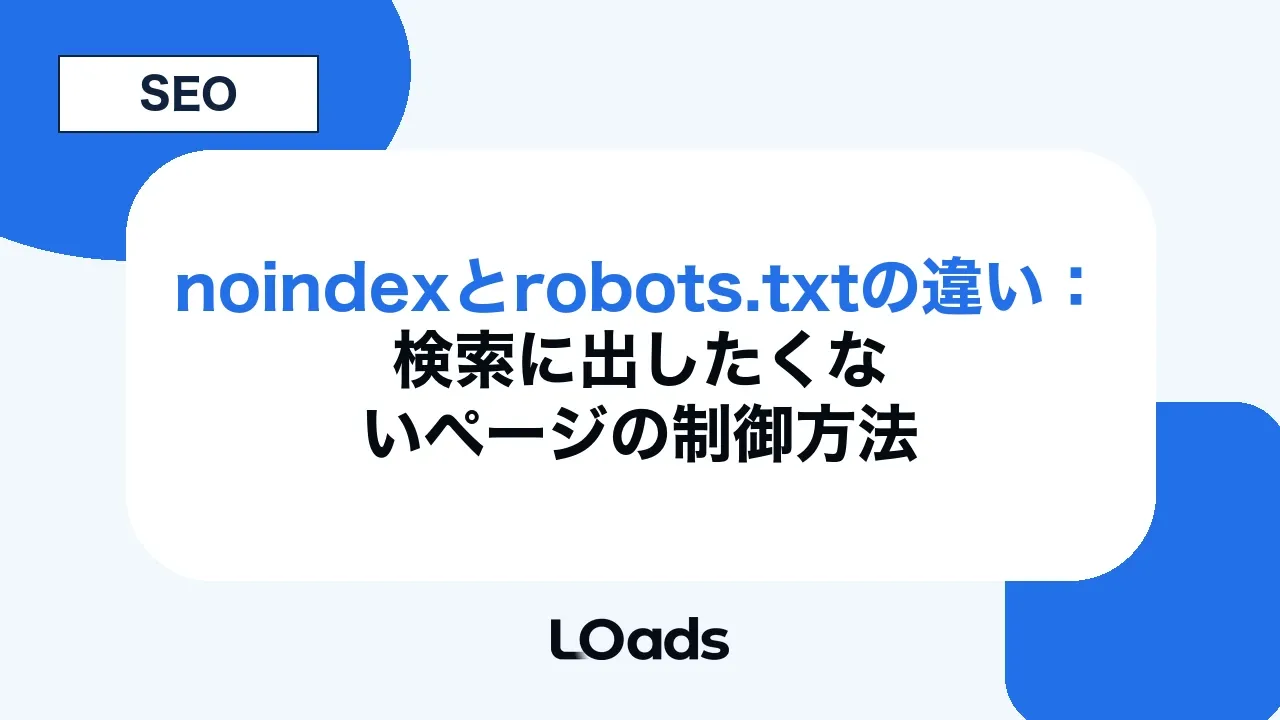
noindexは検索結果に出さないための設定
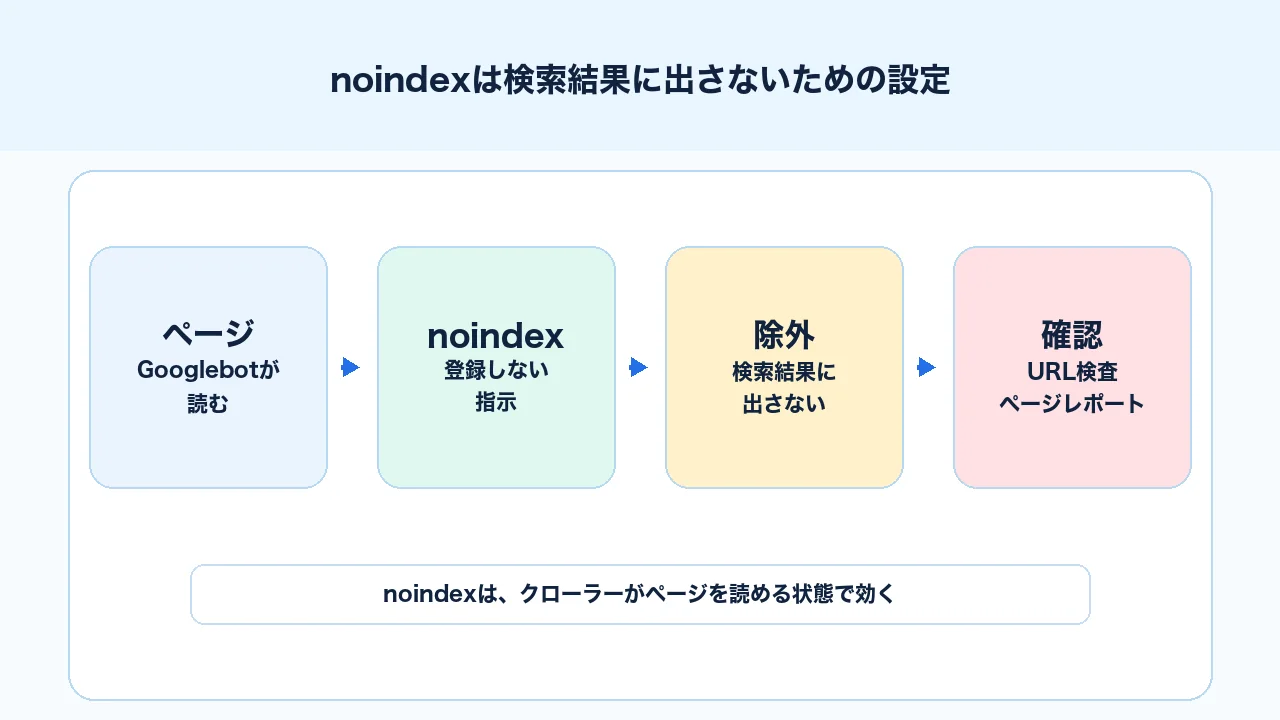
noindexは、検索エンジンに対して「このページをインデックス登録しないでください」と伝える設定です。HTMLのmeta robotsタグ、またはHTTPレスポンスヘッダーのX-Robots-Tagで指定します。Google公式のrobots metaタグとX-Robots-Tagでは、noindex、nofollow、noarchiveなどの指定方法が説明されています。
HTMLで指定する場合は、次のような形です。
```html <meta name="robots" content="noindex"> ```
PDFや画像、HTML以外のファイル、CMSやサーバー側で制御したい場合は、X-Robots-Tagを使うことがあります。
```http X-Robots-Tag: noindex ```
noindexを使う場面は、検索結果に出す必要がないページを除外したい時です。たとえば、次のようなページが候補になります。
| ページ | noindexを検討する理由 |
|---|---|
| 検索結果ページ | 内容が重複しやすい |
| 絞り込み・タグ一覧 | 検索意図に対する独立価値が弱い場合がある |
| サンクスページ | 検索流入の入口にする必要がない |
| 会員向け補助ページ | 一般検索で見せる必要がない |
| 重複・低価値な自動生成ページ | インデックス対象を整理したい |
ここで注意したいのは、noindexはGooglebotがページを読める状態でなければ認識されないことです。ページがrobots.txtでブロックされていると、Googlebotはページ内のmeta robotsを読めません。つまり、検索結果に出したくないページをnoindexで除外したい場合、Googlebotがそのnoindexを確認できる状態にしておく必要があります。
noindexは「検索結果に出さないための指示」です。 ただし、非公開情報を守るためのセキュリティ対策ではありません。ユーザーはURLを知っていればアクセスできる可能性があります。機密情報、管理画面、顧客情報、検証環境などを守りたい場合は、noindexではなく認証やアクセス制限を使います。
管理画面や顧客情報をnoindexだけで守ろうとするのは危険です。noindexは検索結果への表示を制御するための設定であり、アクセス自体を防ぐ仕組みではありません。
BtoBサイトでは、noindexを入れる前に、そのページが検索流入や商談前の判断材料として役割を持つか確認します。サービスページ、事例ページ、比較記事、費用記事、問い合わせ導線に近い記事へ誤ってnoindexを入れると、検索流入の入口を止めることになります。
robots.txtはクロールを制御するための設定
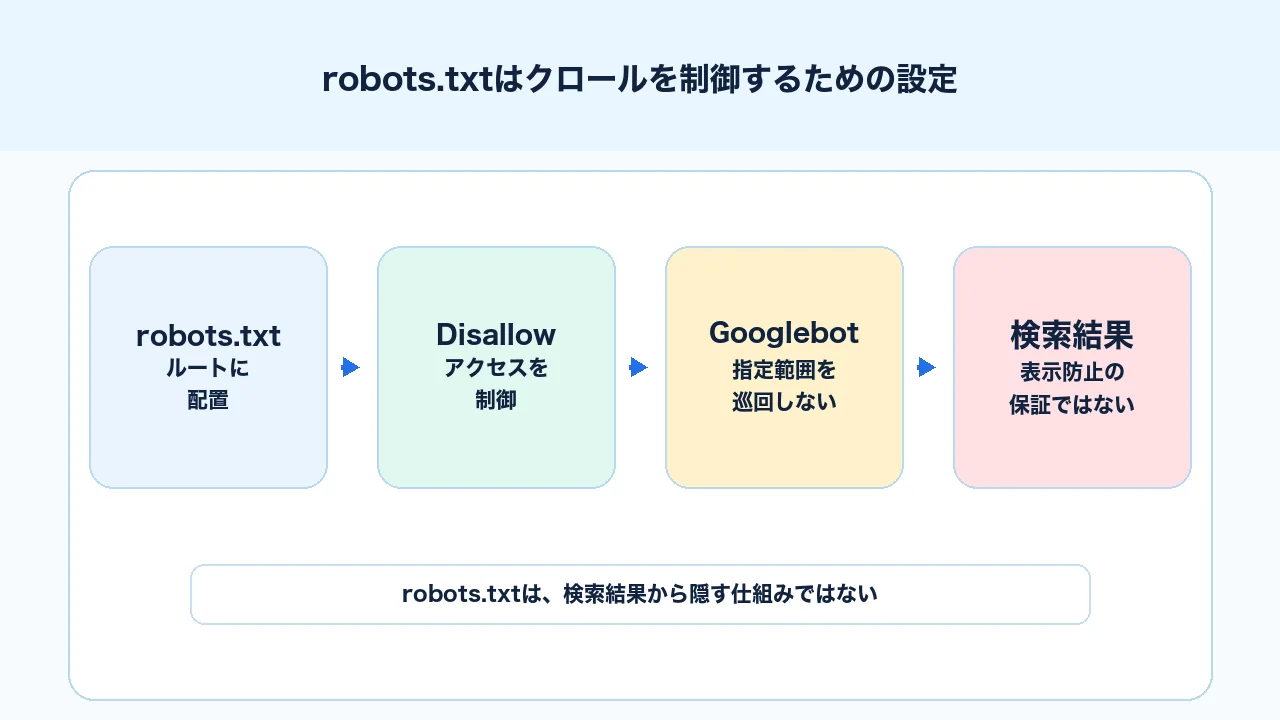
robots.txtは、検索エンジンのクローラーに対して、サイト内のどのURLへアクセスしてよいか、どのURLへアクセスしないでほしいかを伝えるファイルです。通常はサイトのルート直下に設置します。
たとえば、次のような設定は、すべてのクローラーに対して `/admin/` 配下のクロールを制御する例です。
```txt User-agent: * Disallow: /admin/ ```
Google公式のrobots.txt仕様の解釈では、user-agent、allow、disallow、sitemapなどのフィールドや、ファイル形式、キャッシュ、サイズ制限などが説明されています。実務では、ルールの書き方だけでなく、どのURLに対してどのrobots.txtが適用されるかも確認します。
robots.txtを使う主な場面は、クロールさせる必要が低い範囲や、クロール負荷を調整したい範囲を制御する時です。
| 用途 | robots.txtを使う理由 |
|---|---|
| 管理用ディレクトリ | クローラーが巡回する必要がない |
| 絞り込みパラメータ | 大量URLのクロールを抑えたい |
| 検索結果ページ | 無限に近いURL生成を防ぎたい |
| サイト内検索 | クロール対象として重要度が低い |
| 重い生成ページ | サーバー負荷を抑えたい |
ただし、robots.txtは検索結果への表示を完全に止める仕組みではありません。他サイトからリンクされているURLなどは、本文をクロールされなくても、URLだけ検索結果に表示される可能性があります。Google公式のrobots.txt - Search Consoleヘルプでも、robots.txtはページのクロールを防ぐ目的で使用し、検索結果への表示を回避するためには使用しないよう説明されています。
robots.txtは、検索結果から隠すための設定ではなく、クロールを管理するための設定です。検索結果に出したくないページにはnoindex、そもそも見せてはいけない情報には認証やアクセス制限を使います。
使い分けは検索に出すかクロールさせるかで決める

noindexとrobots.txtの使い分けは、「検索に出すか」「クロールさせるか」で決めます。難しく見えますが、判断の軸はシンプルです。
| 目的 | 基本的な設定 | 補足 |
|---|---|---|
| 検索結果に出したくない | noindex | Googlebotがページを読める状態にする |
| クローラーに巡回させたくない | robots.txt | 表示防止の保証ではない |
| 機密情報を守りたい | 認証・アクセス制限 | noindexやrobots.txtでは不十分 |
| 重複ページを整理したい | canonical、統合、noindex | 役割に応じて判断 |
| クロール負荷を調整したい | robots.txt | 大規模サイトやパラメータURLで検討 |
たとえば、サンクスページを検索結果に出したくない場合は、noindexを検討します。サイト内検索結果や大量のパラメータURLをクロールさせたくない場合は、robots.txtを検討します。検証環境や管理画面のように、そもそも第三者に見せてはいけないものは、noindexやrobots.txtではなく、Basic認証、IP制限、ログイン認証などで守ります。
SEOの実務では、設定名から考えるのではなく、ページの目的から考えます。 そのページは検索流入の入口にしたいのか。Googlebotに巡回してほしいのか。ユーザーに見せてよいのか。問い合わせ導線に近いのか。これらを決めてから設定を選びます。
BtoBサイトでよくあるのは、資料ダウンロード後のサンクスページ、フォーム完了ページ、社内確認用ページ、絞り込み一覧、タグ一覧、古い記事一覧、検索結果ページなどです。これらを一律にnoindexにするのではなく、ページの役割ごとに判断します。
たとえば、タグ一覧でも、検索意図に合うカテゴリページとして読者に価値があるならindex対象にする可能性があります。一方で、薄いタグ一覧や重複が多い一覧はnoindexを検討します。robots.txtで止めるか、noindexで除外するか、canonicalで整理するかは、URLの役割と検索価値で決めます。
検索に出したくないならnoindex、クロール負荷や不要巡回を調整したいならrobots.txt、非公開にしたいなら認証という順番で整理します。
noindexとrobots.txtを同時に使う時の注意点

noindexとrobots.txtを同時に使う時に、最も注意したいのは読み取り順です。robots.txtでページをブロックすると、Googlebotはそのページをクロールできません。つまり、ページ内にnoindexが書かれていても、Googlebotがnoindexを読めない可能性があります。
これは実務上かなり重要です。検索結果に出したくないページだからといって、robots.txtでブロックし、さらにページ内にnoindexを入れると、Googlebotがページへアクセスできず、noindexを確認できないことがあります。その結果、URLだけ検索結果に残る、Search Consoleで「robots.txtによりブロック」と表示される、対応方法が分かりにくくなる、といった問題が起きます。
Google公式のrobots.txtによりブロックされているページのブロックを解除するでは、robots.txtルールでブロックされているページが検索結果に表示された場合の確認方法として、URL検査やrobots.txtバリデータ、ルール修正が案内されています。
併用時の考え方は次の通りです。
| 状態 | 起きること | 対応 |
|---|---|---|
| robots.txtでブロック + noindex | noindexを読めない可能性 | 検索除外目的ならクロール許可後にnoindexを読ませる |
| noindexのみ | ページを読んで除外指示を確認できる | 検索結果から除外したい時に使う |
| robots.txtのみ | クロールを制御できる | 検索結果非表示の保証ではない |
| 認証あり | クローラーもユーザーもアクセス不可 | 非公開情報向け |
noindexを効かせたいページは、Googlebotがnoindexを確認できる状態にする必要があります。 そのため、検索結果に出したくないページをnoindexで除外したい場合、robots.txtで同じURLをブロックしていないか確認します。
綱脇耕輔の実務見解として、リニューアル後やCMS移行後に怖いのは、検証環境の設定がそのまま残ることです。ステージングではnoindex、robots.txtブロック、Basic認証が必要でも、本番公開時には検索対象ページだけ解除する必要があります。公開直後にサービスページや記事が検索に出ない場合、本文改善より先にこの設定を確認してください。
CMS・開発環境・不要ページでよくある誤設定
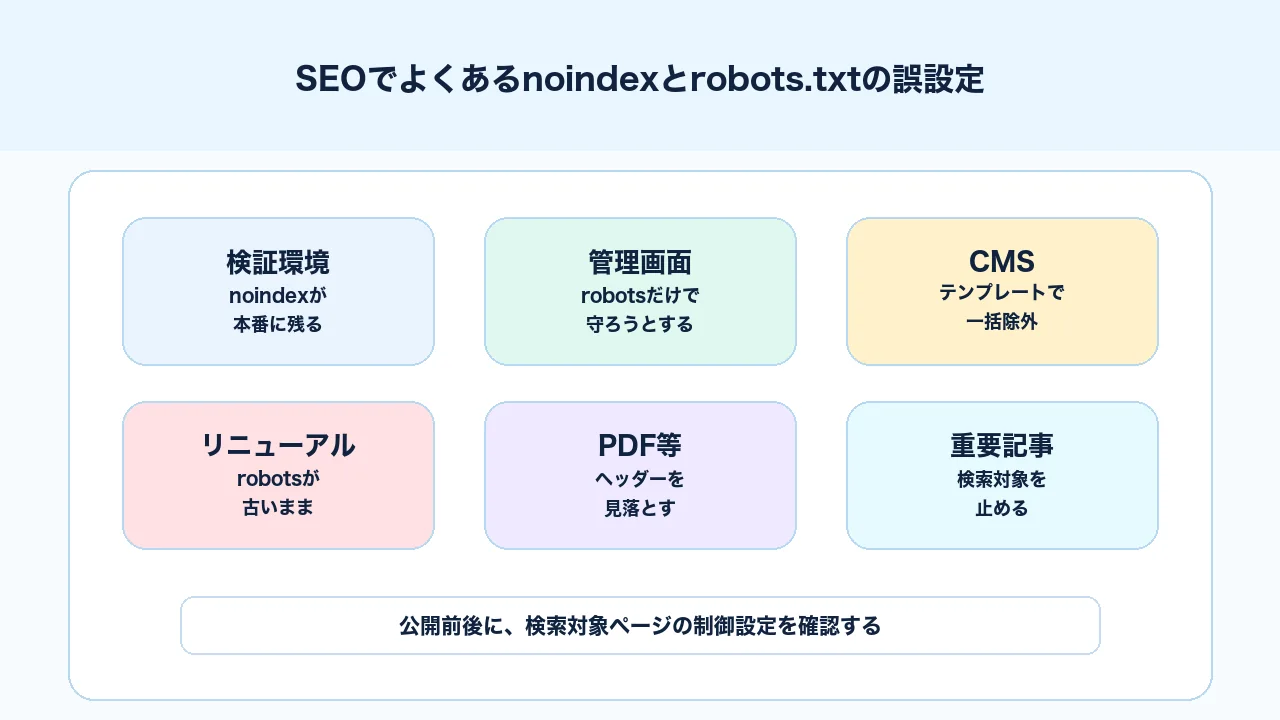
noindexとrobots.txtの問題は、手作業で1ページずつ設定した時だけ起きるわけではありません。CMS、SEOプラグイン、テンプレート、サーバー設定、ステージング環境、本番公開フローの中で起きることが多いです。
よくある誤設定は次の通りです。
| 場面 | よくある誤設定 | 影響 |
|---|---|---|
| 開発環境 | noindexやrobotsブロックが本番に残る | 重要ページが検索に出ない |
| CMSテンプレート | 特定テンプレートに一括noindex | 記事一覧や事例が除外される |
| SEOプラグイン | タグ・カテゴリを一括除外 | カテゴリ導線が検索対象外になる |
| リニューアル | 古いrobots.txtが残る | 新URLのクロールが止まる |
| PDF・ファイル | X-Robots-Tagを見落とす | ファイルが検索に出ない |
| 多言語・サブドメイン | 別ホストのrobotsを見落とす | 一部サイトだけブロックされる |
設定ミスは、ページ単体ではなくテンプレート単位で広がることがあります。 1ページだけの問題に見えても、同じテンプレートを使う複数ページで同じnoindexが出ている場合があります。逆に、robots.txtはドメインやサブドメインごとに適用関係が変わるため、wwwありなし、サブドメイン、HTTP/HTTPSの違いも確認します。
BtoBサイトでは、サービスページ、事例ページ、セミナーLP、資料ダウンロードLP、コラム記事、カテゴリページが別々のCMSやテンプレートで管理されていることがあります。この場合、1つの設定変更がどのページ群に効くのかを把握しておくことが重要です。
noindexとrobots.txtは、設定したページだけでなく、テンプレートやディレクトリ単位で影響が広がることがあります。公開前後のチェックでは、代表URLだけでなく、同じテンプレートの複数URLを確認してください。
Search Consoleでnoindexとrobots.txtを確認する

noindexとrobots.txtは、設定したつもりで終わらせず、Search Consoleで確認します。主に使うのはURL検査、ページのインデックス登録レポート、robots.txtレポートです。
URL検査では、個別URLについて、Googleに登録されているか、Googlebotがクロールを許可されているか、noindexがあるか、Googleが選択した正規URLはどれかなどを確認できます。Google公式のURL検査ツールでは、ページのインデックス登録状態やクロール可否の確認方法が説明されています。
robots.txtレポートでは、Googleが検出したrobots.txt、前回のクロール日、警告やエラーを確認できます。Google公式のrobots.txtレポートでは、レポートの対象や取得ステータス、警告・エラーの見方が説明されています。
確認する流れは次の通りです。
1. 検索に出したい重要URLを選ぶ 2. URL検査で「インデックス登録」「クロール許可」「noindex」の状態を見る 3. robots.txtレポートでファイル取得状況やエラーを見る 4. ページのインデックス登録レポートでnoindex除外やrobotsブロックの傾向を見る 5. 修正後にURL検査やレポートで経過を確認する
| 確認場所 | 見ること | 用途 |
|---|---|---|
| URL検査 | 個別URLの登録状態、robots、noindex | 重要URLの確認 |
| ページレポート | noindex除外、robotsブロックの件数 | サイト全体の傾向 |
| robots.txtレポート | ファイル取得、警告、エラー | robots.txtの確認 |
| ソース確認 | meta robots、X-Robots-Tag | 実装確認 |
| サーバー確認 | ヘッダー、HTTPステータス | 開発・CMS側の原因確認 |
Search Consoleでは、設定そのものではなく、Googleがどう認識したかを確認します。 管理画面でnoindexを外したつもりでも、テンプレートやHTTPヘッダーで残っている場合があります。robots.txtも、古いファイルがキャッシュされていたり、別ホストに対する確認が漏れていたりすることがあります。
修正後は、すぐにすべてが反映されるとは限りません。重要URLはURL検査でライブテストし、必要に応じて再クロールを促し、数日から数週間の単位でページレポートや検索パフォーマンスの変化を確認します。
BtoBサイトでは検索に出すページと出さないページを管理する

BtoBサイトでは、すべてのページを検索結果に出す必要はありません。一方で、検索に出すべきページを誤って止めると、問い合わせや商談に近い入口を失います。noindexとrobots.txtの使い分けは、ページの事業上の役割で管理します。
検索に出したいページの例は次の通りです。
| ページ | 検索に出す理由 |
|---|---|
| サービスページ | 問い合わせに近い |
| 事例ページ | 検討段階の判断材料になる |
| 比較記事 | 商談前の疑問に答える |
| 費用記事 | 予算判断につながる |
| 課題解決記事 | 検索流入の入口になる |
検索に出さない、または慎重に判断したいページの例は次の通りです。
| ページ | 基本方針 |
|---|---|
| フォーム完了ページ | noindexを検討 |
| 検証環境 | 認証・アクセス制限 |
| 管理画面 | 認証・アクセス制限 |
| 低価値なタグ一覧 | noindexや統合を検討 |
| 大量のパラメータURL | robots.txtやURL設計を検討 |
検索に出すページと出さないページを管理することは、SEOの守りの施策です。 記事制作や順位改善の前に、重要ページが検索対象になっているか、不要ページが検索対象に混ざっていないかを確認します。
綱脇耕輔の実務見解として、BtoBサイトでは、制御設定を「SEO担当者だけの作業」にしない方がよいです。制作会社、CMS管理者、エンジニア、広告運用担当、営業企画が関係します。たとえば広告LPをnoindexにするか、サービスページをindex対象にするか、資料ダウンロード完了ページをどう扱うかは、SEOだけでなく運用全体の判断です。
制御設定は、検索流入を増やすためだけでなく、問い合わせ導線を守るためにも管理します。特に重要ページのnoindex、robots.txtブロック、canonical不一致は、公開前後に必ず確認してください。
公開前後のチェックリストで誤設定を防ぐ

noindexとrobots.txtのミスは、公開前後のチェックリストでかなり防げます。属人的に「たぶん大丈夫」と判断するのではなく、検索に出したい重要URLをリスト化し、設定を確認します。
公開前後に見るべき項目は次の通りです。
| チェック項目 | 確認すること | OKの目安 |
|---|---|---|
| 重要URL | 検索に出すページか | サービス・事例・記事が明確 |
| noindex | meta robots、X-Robots-Tag | 重要URLには入っていない |
| robots.txt | Disallowの範囲 | 重要ディレクトリを止めていない |
| HTTPステータス | 200で返るか | 404、500、長いリダイレクトなし |
| canonical | 正規URL | 意図したURLを示している |
| Search Console | URL検査 | クロール可否、登録状態を確認 |
| 変更履歴 | 誰がいつ変えたか | 設定変更を記録 |
チェックリストは、検索に出したいページを守るために使います。 noindexやrobots.txtは、設定自体が悪いのではありません。目的に合わない設定が残ることが問題です。
たとえば、公開前に検証環境をnoindexにするのは自然です。しかし本番公開時にその設定を外し忘れると、重要ページが検索対象外になります。robots.txtで検証環境をブロックするのも自然ですが、本番の重要ディレクトリまでブロックしていないか確認が必要です。
Palcoolでは、技術SEO診断の中で、Search Console、URL検査、robots.txt、noindex、canonical、サイトマップ、内部リンクをまとめて見ます。単に「エラーがあるか」ではなく、事業上重要なURLが検索対象に入っているか、不要なURLが検索対象に混ざっていないかを確認します。
自社で確認する範囲と外部に相談する範囲

noindexとrobots.txtは、自社で確認できる範囲と、外部に相談した方がよい範囲を分けて考えます。設定の意味を理解していれば、初期確認は自社でも可能です。一方で、CMSやサーバー、テンプレート、ヘッダー、リダイレクト、複数ドメインが絡む場合は、外部に相談した方が早いことがあります。
自社で確認しやすいのは、次の項目です。
| 自社で確認 | 確認方法 |
|---|---|
| URL検査 | Search Consoleで個別URLを見る |
| robots.txt | `ドメイン/robots.txt` を開く |
| noindex | ページソースやCMS設定を確認 |
| robots.txtレポート | Search Consoleで取得状況を見る |
| 重要URLリスト | 検索に出すページを整理する |
外部に相談した方がよいのは、次のようなケースです。
| 外部に相談 | 理由 |
|---|---|
| 大量URLがnoindex除外されている | テンプレートやCMSの可能性 |
| robots.txtの影響範囲が分からない | ディレクトリやサブドメイン確認が必要 |
| X-Robots-Tagが残っている | サーバー・ヘッダー確認が必要 |
| リニューアル後に検索流入が落ちた | 設定、URL、canonical、内部リンクを横断確認 |
| 重要ページが検索対象外 | 機会損失が大きいため早期切り分けが必要 |
相談前に準備するとよいのは、検索に出したい重要URLと、検索に出したくないURLのリストです。 これがあると、noindex、robots.txt、canonical、サイトマップ、内部リンクの確認が進めやすくなります。
もし重要ページが検索に出ない、robots.txtで何を止めているか分からない、noindexがどこから出ているか分からない、CMSや開発環境の設定が不安という場合は、早めに診断で切り分ける方が現実的です。
まとめ:noindexとrobots.txtは目的で使い分ける
noindexとrobots.txtは、どちらもSEOで重要な制御設定ですが、目的が違います。noindexは検索結果に出さないための設定です。robots.txtはクロールを制御するための設定です。
検索結果に出したくないページにはnoindexを使います。ただし、Googlebotがnoindexを読める状態である必要があります。robots.txtでブロックしたページにnoindexを置いても、Googlebotが読めない可能性があります。
robots.txtは、クローラーのアクセスを制御したい時に使います。クロール負荷を抑える、不要URLの巡回を防ぐ、大量のパラメータURLを管理するなどの用途です。ただし、検索結果に表示させないための仕組みではありません。
BtoBサイトでは、検索に出すページと出さないページを事業上の役割で管理することが重要です。 サービスページ、事例ページ、比較記事、問い合わせ導線に近い記事を誤って止めないようにし、検証環境、管理画面、重複しやすい一覧は適切に制御します。
noindexとrobots.txtは、設定できることよりも、設定後にどう確認し、誰が運用するかが大切です。Search Console、URL検査、robots.txtレポート、ページソース、HTTPヘッダーを確認し、公開前後のチェックリストで誤設定を防ぎましょう。
よくある質問
noindexとrobots.txtの違いは何ですか?
noindexはページを検索結果に表示させないための設定です。robots.txtはクローラーのアクセスを制御するためのファイルです。検索結果に出したくない場合はnoindex、クロールさせたくない場合はrobots.txtを使います。
robots.txtでブロックすれば検索結果に出ませんか?
検索結果に出ない保証はありません。robots.txtでクロールをブロックしても、外部リンクなどでURLが知られている場合、URLだけ検索結果に表示される可能性があります。検索結果に出したくない場合はnoindexや認証を検討します。
robots.txtでブロックしたページにnoindexを入れてもよいですか?
注意が必要です。robots.txtでブロックするとGooglebotがページをクロールできず、ページ内のnoindexを読めない可能性があります。noindexを効かせたい場合は、Googlebotがそのページを読める状態にする必要があります。
検証環境はnoindexで十分ですか?
検証環境や管理画面など、第三者に見せてはいけないものはnoindexだけでは不十分です。noindexは検索結果への表示を制御する設定であり、アクセス制限ではありません。Basic認証、ログイン認証、IP制限などを使います。
noindexはどこで確認できますか?
ページソース、CMSのSEO設定、HTTPレスポンスヘッダー、Search ConsoleのURL検査やページのインデックス登録レポートで確認します。HTML以外のファイルではX-Robots-Tagでnoindexが出ていることもあります。
BtoBサイトではどのページをnoindexにすべきですか?
一律には決めません。検索流入の入口にしたいサービスページ、事例ページ、比較記事、費用記事は基本的に検索対象です。一方で、フォーム完了ページ、検証環境、管理画面、重複しやすい低価値な一覧などはnoindexや認証、整理を検討します。
参考情報
- noindex を使用してコンテンツをインデックスから除外する
- robots.txt の概要
- Google による robots.txt 仕様の解釈
- robots meta タグと X-Robots-Tag
- robots.txt レポート
- URL 検査ツール
- robots.txt によってブロックされているページのブロックを解除する
アズくんからのお知らせ
関連サービスとして、SEOの支援範囲も確認できます。
集客や問い合わせにつながる施策の優先順位が決まらない場合は、概要ページをご確認ください。
SEOサービスの概要を見る
デジタルマーケティング相談窓口
Web広告やSEOの改善余地を、まずは無料で確認しませんか?
集客をもっと増やしたい、新規施策の見積もりが欲しい、今の業者からの切り替えを考えている場合は、現状の課題から相談できます。
- 集客をもっと増やすにはどうしたらいい?
- 新規施策を行いたいが見積もりが欲しい
- 今の業者からの切り替えを考えている
無料診断を相談する