
クロールとインデックスとは?SEO担当者が知るべき違いと確認方法

SEOで「検索結果に出ない」「記事を公開したのに流入がない」「Search Consoleで未登録と表示される」といった問題が起きたとき、最初に分けて考えたいのがクロールとインデックスです。
クロールは、GooglebotなどのクローラーがURLを見つけ、ページへアクセスして内容を取得する工程です。インデックスは、取得されたページが検索エンジンのデータベースに整理され、検索結果に出る候補へ入る工程です。つまり、クロールされたからといって、必ずインデックス登録されるわけではありません。
結論から言うと、クロールとインデックスの違いを理解する目的は、用語を覚えることではなく、検索に出ない原因が「見つかっていない」のか、「取得できていない」のか、「取得されたが登録されていない」のかを切り分けることです。ここを混同すると、サイトマップを出せばよいのか、内部リンクを直すべきなのか、noindexやcanonicalを確認すべきなのか、コンテンツの価値や重複を見直すべきなのかが判断できません。
BtoBサイトでは、すべてのURLを同じ重みで見る必要はありません。まずはサービスページ、事例ページ、問い合わせ導線に近い記事、検索流入の入口になっている記事から確認します。重要ページがクロールされていない、またはインデックス登録されていない場合、検索流入だけでなく問い合わせ機会の損失にもつながります。
この記事では、クロールとインデックスの違い、GooglebotがURLを見つける仕組み、インデックス登録の考え方、Search Consoleでの確認方法、サイトマップ・内部リンク・noindex・robots.txt・canonicalの見方、BtoBサイトでの優先順位まで整理します。未インデックスの個別原因や改善方法はNo35で深掘りするため、本記事ではまず「仕組みと確認方法」を押さえます。
補足ボックス|この記事でわかること
- クロールとインデックスの違い
- GooglebotがURLを発見して取得する流れ
- インデックス登録が検索結果に出る候補である理由
- Search Consoleで確認すべき場所
- サイトマップ、内部リンク、noindex、robots.txt、canonicalの基本
- BtoBサイトで優先して確認すべきURL
- 自社で確認する範囲と外部に相談する範囲
補足ボックス終了
クロールとインデックスは検索に出るまでの別工程
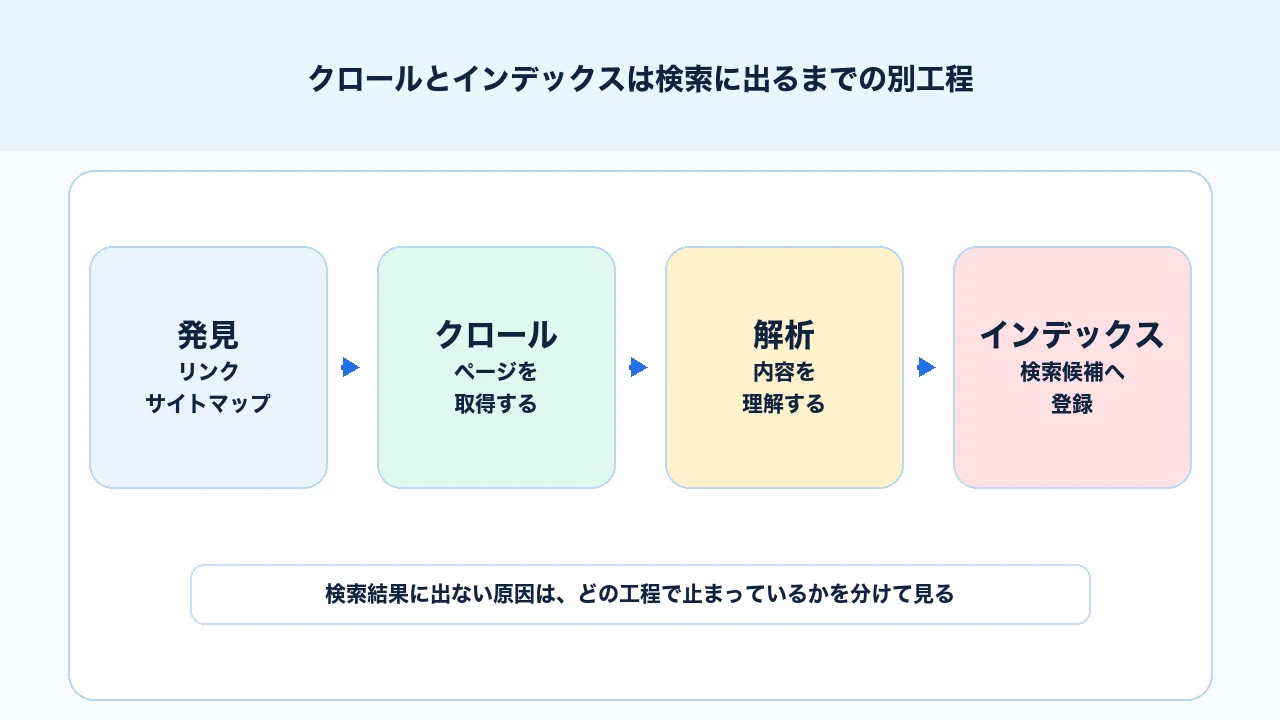
クロールとインデックスは、検索結果にページが表示されるまでの別工程です。Google検索の仕組みは、ページを見つける、クロールする、内容を理解する、インデックスに登録する、検索語句に応じてランキングする、という流れで考えると理解しやすくなります。Google公式の検索の仕組みでも、URLの検出、クロール、インデックス登録、検索結果表示の流れが説明されています。
クロールは、Googlebotがページへアクセスし、HTMLや関連リソースを取得する段階です。インデックスは、取得したページの内容を解析し、検索結果に表示できる候補として整理する段階です。ランキングは、検索クエリに対してどのページをどの順番で表示するかを決める段階です。
この3つを分けて考えないと、原因の切り分けを間違えます。たとえば、ページが検索結果に出ない場合でも、原因は複数あります。
| 状態 | 何が起きているか | まず見ること |
|---|---|---|
| 発見されていない | GoogleがURLを知らない | 内部リンク、サイトマップ |
| クロールされていない | URLはあるが取得されていない | robots.txt、サーバー、URL検査 |
| クロール済み未登録 | 取得されたがインデックスに入っていない | 重複、品質、canonical、noindex |
| 登録済みだが流入なし | 検索候補には入っているが選ばれていない | title、検索意図、CTR、順位 |
| 流入はあるがCVなし | 検索から来ても行動につながらない | CTA、内部リンク、サービス導線 |
SEO担当者が最初に行うべきことは、検索に出ないページを一括りにせず、どの工程で止まっているかを見ることです。 これは用語の理解というより、調査の順番を間違えないための実務判断です。
綱脇耕輔の実務見解として、BtoBサイトでは「インデックスされているか」だけを見ても不十分です。サービスページが登録されていても、そこへつながる記事がクロールされていない場合があります。逆に記事が登録されていても、問い合わせ導線に近いページへ内部リンクがない場合もあります。検索流入から問い合わせまでを考えるなら、URL単位の状態とサイト内導線をセットで見ます。
クロールとインデックスは、検索順位の前にある土台です。順位改善や記事追加を考える前に、重要URLが発見され、取得され、検索候補に入っているかを確認してください。
GooglebotがURLを発見してクロールする仕組み

Googlebotは、すでに知っているURL、ページ内のリンク、外部サイトからのリンク、サイトマップ、リダイレクトなどをたどってURLを発見します。URLを見つけた後、Googlebotがそのページにアクセスし、内容を取得します。Google公式のクロールとインデックス登録に関するトピックでは、Googleがコンテンツを見つけ、解析し、検索に表示するための管理項目が整理されています。
クロールで重要なのは、GooglebotがURLに到達できることです。URLが存在していても、内部リンクがなければ発見されにくくなります。サイトマップに入っていても、robots.txtでブロックされていたり、サーバーエラーが返っていたり、ログインが必要だったりすると、正常にクロールされません。
GooglebotがURLを発見する主な経路は次の通りです。
| 発見経路 | 役割 | 確認すること |
|---|---|---|
| 内部リンク | サイト内の重要ページへ案内する | 孤立ページがないか |
| 外部リンク | 他サイトからURLを発見する | 重要ページへの外部言及 |
| XMLサイトマップ | 重要URLや更新URLを通知する | noindexや404が混ざっていないか |
| リダイレクト | 移転先URLを伝える | 連鎖やループがないか |
| Search Console | URLの状態を確認する | URL検査、ページレポート |
BtoBサイトでは、サービスページや事例ページがトップページから何クリックも離れていたり、記事からサービスページへの内部リンクが弱かったりすることがあります。この状態では、GooglebotがURLを見つけられても、サイト内でどのページが重要なのか伝わりにくくなります。
内部リンクは、読者の導線であると同時に、Googlebotが重要URLを見つけるための道でもあります。 重要なサービスページ、事例ページ、比較記事、問い合わせ導線に近いページには、関連する記事やカテゴリページから自然にリンクを集めます。
Google公式は、ページ追加や変更後にGoogleへ再クロールをリクエストする方法として、URL検査ツールやサイトマップを案内しています。詳しくはクロール・インデックス登録リクエストでも確認できます。ただし、リクエストは登録や順位を保証するものではありません。
「サイトマップを送ったから必ずクロール・インデックスされる」と考えるのは危険です。サイトマップはURL発見の補助であり、ページ品質、重複、正規化、サイト内リンク、技術設定もあわせて確認する必要があります。
インデックス登録は検索結果に出る候補へ入ること

インデックス登録は、Googleがページを検索結果に出す候補として整理する工程です。ここで大切なのは、クロールされたページがすべてインデックス登録されるわけではないことです。
Googleはページをクロールした後、内容を解析し、重複ページかどうか、正規ページはどれか、検索結果に表示する価値があるかなどを判断します。Google公式のクロールとインデックス登録に関するFAQでも、サイトマップがインデックス登録や掲載順位を保証するものではないことが説明されています。
Search Consoleでは、ページがインデックス登録されているか、未登録なのか、クロール済みなのか、検出されたが未クロールなのかといった状態を確認できます。URL検査ツールでは、個別URLについてインデックス登録の状態、クロール情報、正規URL、ページの取得可否などを確認できます。公式ヘルプのURL検査ツールも参考になります。
インデックス登録を理解するときは、次のように分けて見ると整理しやすくなります。
| 状態 | 意味 | 次に見ること |
|---|---|---|
| URLはGoogleに登録されています | 検索結果に出る候補に入っている | 検索クエリ、CTR、順位 |
| 検出 - インデックス未登録 | URLは見つかっているが未取得または未処理 | 内部リンク、サイトマップ、重要度 |
| クロール済み - インデックス未登録 | 取得されたが登録されていない | 重複、品質、canonical、noindex |
| 代替ページ | 別URLが正規と判断されている | canonical、重複、URL設計 |
| noindex | 登録しない指示がある | 意図した除外か誤設定か |
ここで注意したいのは、Search Consoleの状態名だけで即断しないことです。「クロール済み - インデックス未登録」と出ていても、必ずしもエラーとは限りません。重複ページ、低品質な一覧ページ、検索結果に出す必要がないURLであれば、未登録でも問題ない場合があります。一方で、サービスページや主要記事が未登録なら優先的に確認すべきです。
インデックス登録は、検索結果に出る候補へ入る工程であり、登録された後に初めて順位やCTRの改善を考えられます。登録前のURLに対してタイトル改善やリライトだけを行っても、問題の本質がクロールや登録可否にある場合は改善しにくくなります。
レンダリング・正規化・品質判断も分けて見る
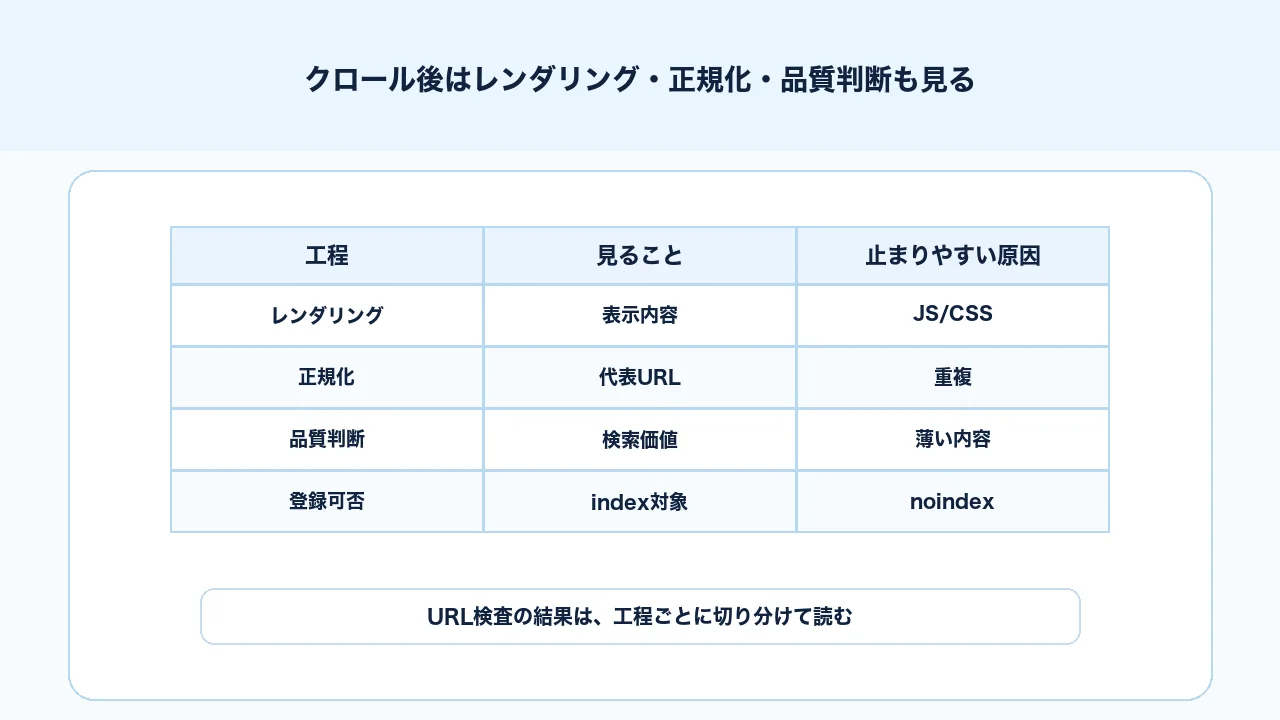
クロールとインデックスの間には、レンダリング、正規化、品質判断などの確認観点があります。ここを飛ばすと、「クロールされたのに検索に出ない」理由を見誤ります。
レンダリングは、Googleがページを表示・解釈する工程です。JavaScriptで主要コンテンツを出しているサイト、CMSの出力が複雑なサイト、ログインや同意画面の影響を受けるサイトでは、Googlebotが見ている内容とユーザーが見ている内容がずれることがあります。
正規化は、同じまたは似た内容の複数URLの中から、代表URLを選ぶ考え方です。canonicalを指定していても、Googleが別のURLを正規URLとして選ぶことがあります。Google公式の重複URLを統合する方法では、canonicalやリダイレクト、サイトマップなどを使った正規化の考え方が説明されています。
品質判断は、検索結果に表示する価値があるかどうかの判断に関わります。薄いページ、重複が多いページ、自動生成に近いページ、検索意図に答えていないページは、クロールされてもインデックスに登録されにくい場合があります。
確認観点を分けると、次のようになります。
| 観点 | 確認すること | よくある問題 |
|---|---|---|
| 取得 | Googlebotがページへアクセスできるか | 403、500、robotsブロック |
| レンダリング | 主要コンテンツが見えているか | JS依存、表示遅延、空コンテンツ |
| 正規化 | 代表URLが意図通りか | canonical不一致、重複URL |
| 登録可否 | noindexなどで除外していないか | 誤ったnoindex、X-Robots-Tag |
| 品質 | 検索に出す価値があるか | 重複、薄い内容、意図ずれ |
URL検査ツールの結果は、単なる合否ではなく、どの工程に問題があるかを見るための材料です。 「URLはGoogleに登録されています」と出ても、選ばれている正規URL、最終クロール日時、クロールされたページの内容、サイトマップ検出状況を確認します。
綱脇耕輔の実務見解として、BtoBサイトでは「記事の品質」と「サイト内での役割」が混ざりやすいです。記事単体ではよく書けていても、サービスページや関連する比較記事へつながっていなければ、サイト全体では弱いページとして扱われることがあります。インデックスの問題を考えるときも、ページ単体とサイト内導線の両方を見る必要があります。
Search Consoleでクロールとインデックスを確認する

クロールとインデックスの確認では、Search Consoleを使います。大きく分けると、URL検査ツールで個別URLを確認し、ページレポートでサイト全体の傾向を確認します。
URL検査ツールでは、特定のURLについて、Googleに登録されているか、クロールされた日時、インデックス登録を妨げる要因、Googleが選択した正規URLなどを確認できます。ページ単位で原因を確認したいときに使います。
一方、ページレポートでは、サイト全体で登録済み、未登録、除外、エラーに近い状態がどれくらいあるかを見ます。サイト全体の傾向を把握したいときに使います。Search Consoleの一般的なタスクでは、インデックス状況を確認し、必要に応じてサイトマップや再クロールのリクエストを使うことが説明されています。
確認の基本手順は次の通りです。
1. 重要URLを決める 2. URL検査ツールで個別URLを確認する 3. 登録済みか、未登録か、正規URLは意図通りかを見る 4. ページレポートで同じ状態のURLが多いか確認する 5. サイトマップ、内部リンク、noindex、canonical、内容の重複を確認する 6. 対応後、再クロールやサイトマップ更新を行う 7. 数日から数週間の単位で変化を確認する
ここで大切なのは、1つのURLだけを見て全体判断しないことです。1ページだけの問題なら個別対応で済むことがありますが、同じテンプレートのページが大量に未登録なら、CMS、カテゴリ設計、重複、サイトマップ、内部リンクに共通問題がある可能性があります。
Search Consoleでは、1URLの状態とサイト全体の傾向を分けて確認します。BtoBサイトであれば、サービスページ、事例ページ、主要記事、問い合わせ導線に近い記事を優先してURL検査し、次にページレポートで同じ傾向が広がっていないかを確認します。
サイトマップと内部リンクで重要URLを見つけてもらう
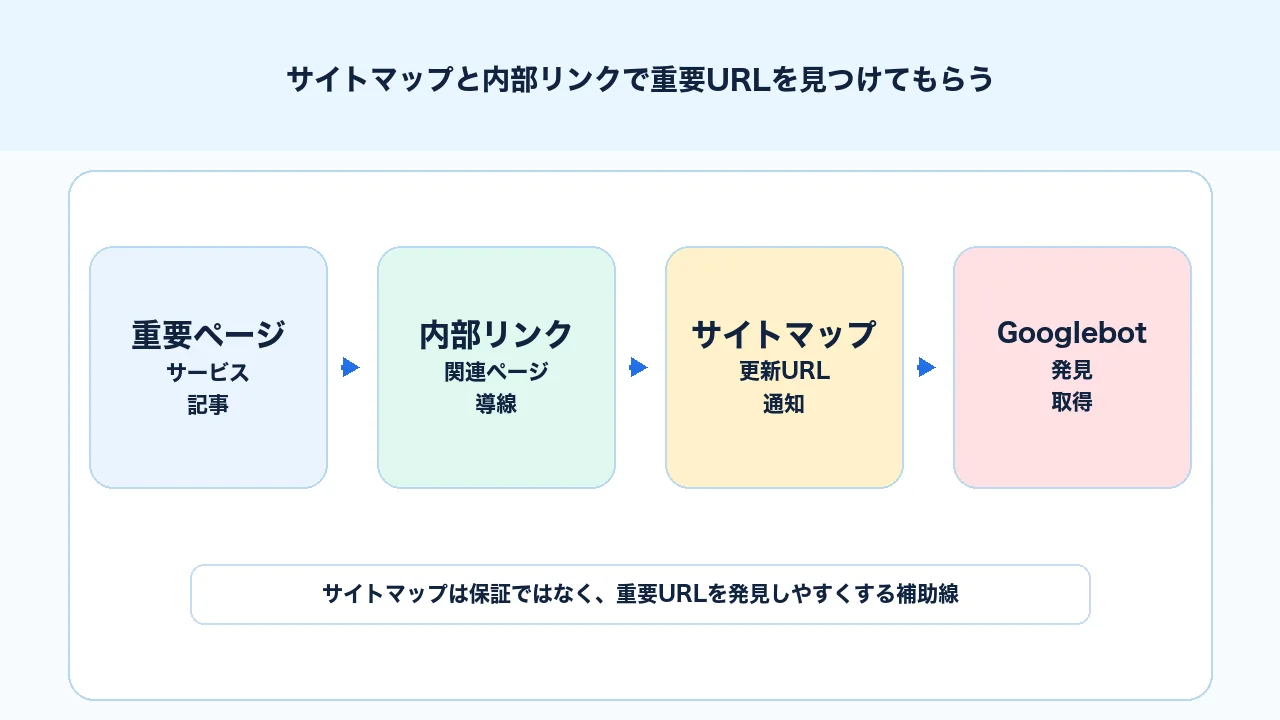
サイトマップと内部リンクは、Googleに重要URLを見つけてもらうための基本です。ただし、サイトマップはインデックス登録を保証するものではありません。Google公式のサイトマップの作成と送信でも、サイトマップはGoogleにページを知らせる手段として説明されています。
サイトマップに入れるべきなのは、検索結果に出したい正規URLです。noindexページ、404ページ、リダイレクト元URL、canonicalで別URLを指しているページを大量に入れると、サイトマップの品質が下がります。
内部リンクは、サイト内で重要ページへ到達しやすくするために使います。検索流入のある記事から関連する深掘り記事、費用記事、比較記事、サービスページへつなげることで、読者もGooglebotもページの関係を理解しやすくなります。
確認したいポイントは次の通りです。
| 項目 | 確認すること | 改善例 |
|---|---|---|
| XMLサイトマップ | 重要な正規URLだけが入っているか | noindex、404、リダイレクト元を除外 |
| 内部リンク | 重要ページへ自然にリンクがあるか | 関連記事やカテゴリからリンク追加 |
| 孤立ページ | どこからもリンクされていないURLがないか | 親記事、カテゴリ、一覧から接続 |
| URL階層 | サイト構造が分かりやすいか | カテゴリ、パンくず、URLを整理 |
| 更新URL | 新規・更新ページが伝わるか | サイトマップ更新、内部リンク追加 |
サイトマップはGoogleへの通知、内部リンクはサイト内の重要度と導線を伝える手段です。 どちらか一方だけで考えるのではなく、両方を見ます。
BtoBサイトでは、検索流入がある記事からサービスページへの内部リンクが弱いことがあります。この場合、記事はインデックスされていても、問い合わせに近いページへ読者が進めません。クロール・インデックス確認の段階でも、単にURLが登録されているかを見るだけでなく、ページ同士のつながりを確認してください。
noindex・robots.txt・canonicalの役割を間違えない
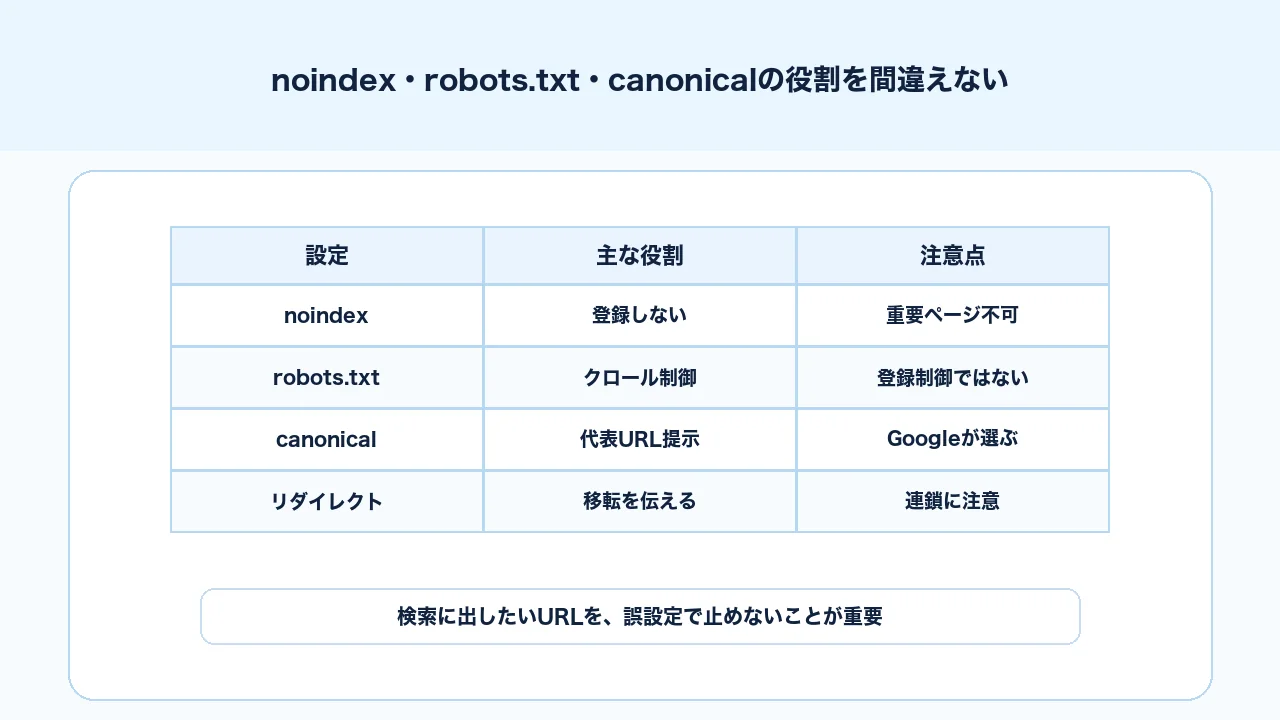
クロールとインデックスで混同しやすいのが、noindex、robots.txt、canonicalです。これらは似ているようで役割が違います。
noindexは、ページをインデックス登録しないように伝えるための指定です。Google公式のrobots metaタグとX-Robots-Tagでは、noindexを含むmetaタグやHTTPヘッダーの考え方が説明されています。
robots.txtは、クローラーのアクセスを制御するためのファイルです。Google公式のrobots.txtの概要でも、クロールの制御に使うものとして説明されています。robots.txtでブロックしても、URLが別経路で知られている場合、検索結果にURLだけが表示されることがあります。つまり、robots.txtはインデックス登録の制御そのものではありません。
canonicalは、重複または類似ページの中で、どのURLを代表として扱ってほしいかを伝える指定です。ただし、Googleが必ず指定通りに選ぶとは限りません。Search ConsoleでGoogleが選択した正規URLを確認することが重要です。
| 設定 | 主な役割 | よくある誤解 |
|---|---|---|
| noindex | インデックス登録しないように伝える | クロールを止める設定だと思う |
| robots.txt | クロールを制御する | インデックス登録を完全に止めると思う |
| canonical | 代表URLを示す | 必ず指定通り選ばれると思う |
| リダイレクト | URL移転を伝える | 長い連鎖でも問題ないと思う |
検索に出したい重要ページへnoindexを入れる、robots.txtで重要ディレクトリをブロックする、canonicalを別URLへ誤って向けるといった設定ミスは、流入機会を大きく失う可能性があります。公開前後のチェックリストに必ず入れてください。
綱脇耕輔の実務見解として、CMS移行やサイトリニューアル後に多いのは、検証環境のnoindex、不要なrobots.txt制御、古いcanonical設定が本番へ残るケースです。記事品質の問題ではなく設定事故なので、早く見つけるほど損失を抑えられます。
BtoBサイトでは重要ページから優先して確認する
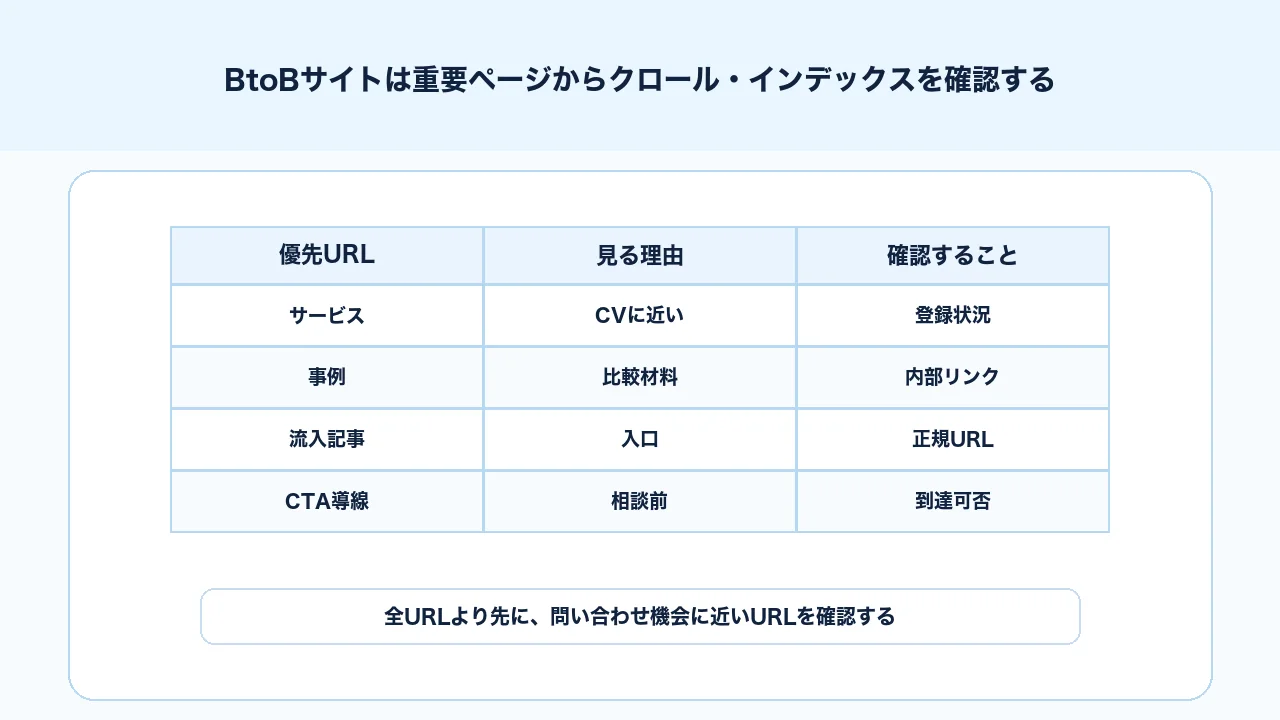
クロールとインデックスの確認は、全URLを同じ優先度で見る必要はありません。特にBtoBサイトでは、問い合わせや商談につながるURLから確認します。
優先度が高いのは、サービスページ、料金や費用に関するページ、事例ページ、比較記事、問い合わせ導線に近い記事、検索流入が多い記事です。これらのページが未登録、noindex、canonical不一致、内部リンク不足になっていると、検索流入や問い合わせに影響しやすくなります。
一方で、タグ一覧の2ページ目、重複しやすい検索結果ページ、低価値なアーカイブ、管理用URLなどは、インデックス登録されていなくても問題ない場合があります。むしろ検索に出さない方がよいURLもあります。
優先順位は次のように整理できます。
| 優先度 | URLの種類 | 確認する理由 |
|---|---|---|
| 高 | サービスページ、問い合わせ導線 | CVに近く、機会損失が大きい |
| 高 | 事例ページ、比較記事 | 検討段階の判断材料になる |
| 中 | 検索流入の入口記事 | 回遊とサービス導線に関係する |
| 中 | カテゴリページ、親記事 | 記事群の整理に関係する |
| 低 | タグ2ページ目、重複一覧 | 登録不要な場合がある |
BtoBサイトでは、重要URLが検索に出る状態か、そこへ読者とGooglebotが到達できるかを優先して確認します。登録済みURL数を増やすことが目的ではありません。問い合わせや商談につながるページの機会損失を減らすことが目的です。
Search Consoleのページレポートで未登録URLが多いと不安になりますが、まずは重要URLに絞ります。全体の未登録数より、重要ページの状態、テンプレート単位の問題、同じ原因が広がっているかを確認してください。
この記事もおすすめ|SEOコンサルとは?依頼できること・費用・会社選びのポイント|SEO内部対策や技術SEOを外部に相談する範囲を整理したい場合はこちらを参照してください。|記事を読む →
クロール・インデックスでよくある失敗例
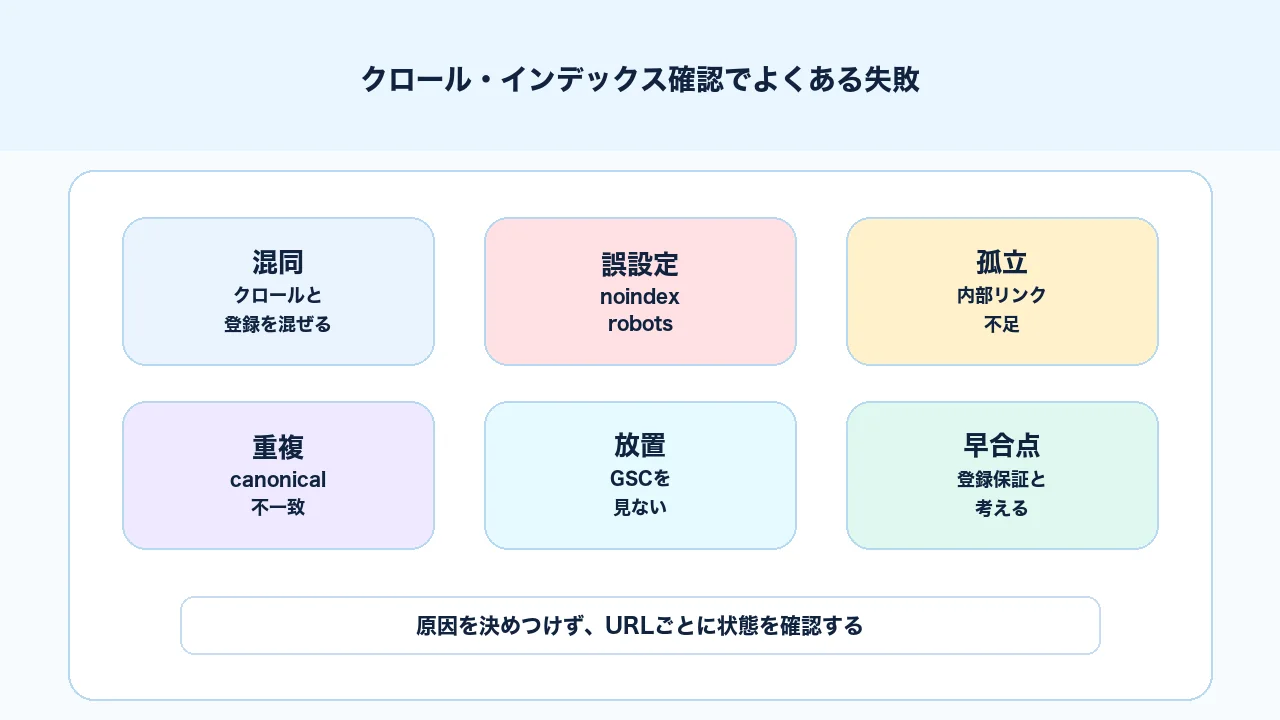
クロール・インデックス確認でよくある失敗は、状態名だけで原因を決めつけることです。「クロール済み - インデックス未登録」と出たらすぐにリライトする、「検出 - インデックス未登録」と出たらすぐにURL検査で登録リクエストする、といった対応は、原因を見ないまま作業している状態です。
よくある失敗を整理すると、次のようになります。
| 失敗 | 起きる問題 | 改善方向 |
|---|---|---|
| クロールとインデックスを混同する | 調査の順番を間違える | 発見、取得、登録、順位を分ける |
| URL検査だけで判断する | サイト全体の傾向を見落とす | ページレポートと合わせて見る |
| サイトマップを万能だと思う | 内部リンク不足を放置する | 重要ページへリンクを作る |
| noindex確認をしない | 重要ページが除外される | 本番公開前後に確認する |
| canonicalを見ない | 意図しないURLが代表になる | Google選択の正規URLを見る |
| 登録数だけを追う | 不要URLまで増える | CVに近いURLを優先する |
クロール・インデックスの確認は、技術チェックでありながら、事業上の優先順位も必要です。 検索に出すべきURLと出さなくてよいURLを分け、重要URLから確認します。
もう一つの失敗は、すぐに成果を期待しすぎることです。クロールやインデックス登録には時間がかかる場合があります。Google公式FAQでも、URLのクロールやインデックス登録の時期、実際に行われるかどうかを予測・保証できないことが説明されています。登録リクエストを何度も送るより、ページが検索に出す価値を持っているか、内部リンクやサイトマップで発見しやすいかを整える方が重要です。
自社で確認する範囲と外部に相談する範囲

クロールとインデックスの基本確認は、自社でも進められます。Search ConsoleのURL検査、ページレポート、サイトマップ、noindexの有無、内部リンクの有無は、担当者が確認しやすい範囲です。
一方で、CMSやJavaScript、canonicalの大量不一致、リニューアル後のURL移行、テンプレート単位のnoindex、サーバーエラー、重要ページの大量未登録などは、外部に相談した方が早い場合があります。原因が技術、コンテンツ、サイト構造、導線のどこにあるかを切り分ける必要があるためです。
自社確認と外部相談の境界は、次のように考えると分かりやすくなります。
| 範囲 | 自社で確認しやすいこと | 外部に相談した方がよいこと |
|---|---|---|
| URL検査 | 登録状態、クロール日時、noindex | 正規URL不一致の原因分析 |
| サイトマップ | 送信状況、重要URLの有無 | CMS自動生成ルールの整理 |
| 内部リンク | 重要ページへのリンク有無 | 記事群と導線の再設計 |
| 技術設定 | 明らかなnoindex、robots確認 | JS、サーバー、リダイレクト設計 |
| 優先順位 | 重要URLの洗い出し | CV距離と投資判断の整理 |
綱脇耕輔の実務見解として、相談前に準備しておくとよいのは「検索に出したい重要URLのリスト」です。すべての未登録URLを持ち込むより、サービスページ、事例ページ、主要記事、問い合わせ導線に近いページを10〜30URLほど整理しておくと、診断の精度が上がります。
もしクロール・インデックスの状態でお困りであれば、まずは重要URLの状態を整理してください。URL検査の結果、ページレポートの傾向、サイトマップ、内部リンク、noindex、canonicalを見れば、原因の方向性はかなり見えます。判断に迷う場合は、サイトSEO診断で対応範囲と優先順位を切り分けると進めやすくなります。
まとめ:クロールとインデックスは検索流入の入口を確認する基本
クロールとインデックスは、SEOの技術用語であると同時に、検索流入の入口を確認するための基本です。クロールはGooglebotがURLを見つけて取得する工程、インデックスは検索結果に出る候補へ入る工程です。
検索に出ないページがあるときは、まず発見されているか、クロールされているか、インデックス登録できる状態か、GoogleがどのURLを正規として見ているかを分けて確認します。そのうえで、重要ページから優先順位を付けます。
BtoBサイトでは、インデックス登録数そのものより、問い合わせや商談に近いURLが検索に出る状態かを確認することが重要です。 サービスページ、事例ページ、比較記事、主要な流入記事、CTA導線に近いページから見てください。
クロールとインデックスの仕組みを理解しておくと、Search Consoleの状態を見たときに、何を直すべきか判断しやすくなります。記事追加や順位改善の前に、検索に出る土台が整っているかを確認しましょう。
よくある質問
クロールとインデックスの違いは何ですか?
クロールはGooglebotがURLを見つけてページ内容を取得する工程です。インデックスは取得したページが検索結果に出る候補としてGoogleのデータベースに整理される工程です。クロールされたからといって、必ずインデックス登録されるわけではありません。
クロールされていれば検索結果に出ますか?
必ず出るわけではありません。noindex、重複、canonical、コンテンツ品質、検索に出す必要性などの要因により、クロールされてもインデックス登録されない場合があります。
Search Consoleでは何を確認すればよいですか?
個別URLはURL検査ツールで確認し、サイト全体の傾向はページレポートで確認します。登録状態、クロール日時、Googleが選択した正規URL、noindex、サイトマップ検出状況などを見ます。
サイトマップを送ればインデックスされますか?
サイトマップはGoogleがURLを発見しやすくするための補助です。インデックス登録や順位上昇を保証するものではありません。重要URLへの内部リンク、ページ品質、正規化、noindexなども確認する必要があります。
BtoBサイトではどのURLから確認すべきですか?
サービスページ、事例ページ、比較記事、問い合わせ導線に近い記事、検索流入の入口になっている主要記事から確認します。登録済みURL数を増やすことより、問い合わせ機会に近いURLの状態を見ることが重要です。
参考情報
- Google 検索の仕組み
- Google のクロールとインデックス登録
- クロール・インデックス登録リクエスト
- URL 検査ツール
- サイトマップの作成と送信
- robots metaタグとX-Robots-Tag
- robots.txtの概要
- 重複URLを統合する方法
アズくんからのお知らせ
関連サービスとして、SEOの支援範囲も確認できます。
集客や問い合わせにつながる施策の優先順位が決まらない場合は、概要ページをご確認ください。
SEOサービスの概要を見る
デジタルマーケティング相談窓口
Web広告やSEOの改善余地を、まずは無料で確認しませんか?
集客をもっと増やしたい、新規施策の見積もりが欲しい、今の業者からの切り替えを考えている場合は、現状の課題から相談できます。
- 集客をもっと増やすにはどうしたらいい?
- 新規施策を行いたいが見積もりが欲しい
- 今の業者からの切り替えを考えている
無料診断を相談する